Free Cisco 300-810 Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for 300-810 CLICA certification exam which are developed and validated by Cisco subject domain experts certified in Cisco 300-810 . These practice questions are update regularly as we keep an eye on any recent changes in 300-810 CLICA syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Cisco 300-810 exam questions and pass your exam on first try.
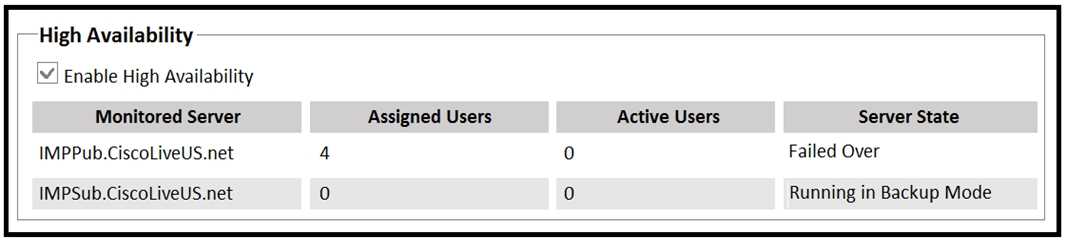
A customer reports that after a network failure, all of the Cisco Jabber clients are not switched back
to their home nodes. An engineer determines that the primary Cisco IM&P server is in Failed Over
state. Which two actions should be performed to bring the system back to operational state and to
prevent future occurrences? (Choose two.)
B imo, since making sure both servers are properly in the redundancy group is basic but crucial. D also fits because manually clicking Fallback is the direct way to recover from a failed over state without waiting for restarts.
Option C makes sense since restarting the primary server can trigger fallback if it’s stuck. Also, B seems important to double-check both servers are correctly set up in the redundancy group to avoid failover issues later.
reports that they cannot control their desk phone from the Cisco Jabber client. Which action must
the engineer take to verify the service connections of the Cisco Jabber client?
I’m thinking B might also be a strong choice here since the XML settings reveal the URLs Jabber uses to connect to services like the desk phone. If those URLs are wrong or missing, that could explain why phone control isn’t working. Just checking connection status (A) might show if it’s connected but won’t confirm if the right services are configured. Could the issue be more about the service configuration rather than just connection status?
A, it shows all active connections clearly in Jabber.
Service does the Cisco TSP Instance communicate with directly?
Maybe C could be right because the TSP instance might need to interact with the Cisco CallManager Service for actual call signaling, not just CTI data. The question is about direct communication, so it’s worth considering.
Option A since TSP needs direct CTI control, not just call routing.
configured the transfer rules that specify how Unity Connection transfers the calls that reach the call
handler from the automated attendant. Which call handler setting must be configured to specify
whether callers can perform transfers?
A imo, since caller input settings usually define what actions callers can take, including transfers. Transfer rules set where calls go, but enabling transfers is controlled in caller input.
This question seems a bit confusing. The transfer rules are mentioned as already configured, but the question asks about the call handler setting that controls if callers can do transfers. Is it about enabling transfer during the call handler process or something else? Could use some clarification on what exactly is meant by "specify whether callers can perform transfers" here.
Connection system is integrated with two phone systems each with its own trunk access code Which
figuration blocks attempts to bypass the restriction table by dialing trunk access codes?
I get the logic behind A, but I’m going with D here. Blocking all international calls (D) stops any bypass that leads to expensive routes, which is usually the main fraud risk. Just blocking trunk codes (A) might not catch crafty users who dial international numbers directly. So, D feels like a safer overall filter against toll fraud by cutting off high-risk destinations completely.
I get why A is popular, but I think B makes more sense here. If you just block the trunk access codes (A), users might find other ways to transfer or reroute calls. Restricting transfer numbers (B) cuts off all potential bypass routes, not just the obvious trunk codes. So B feels like a safer, broader way to prevent toll fraud without relying only on pattern matching.
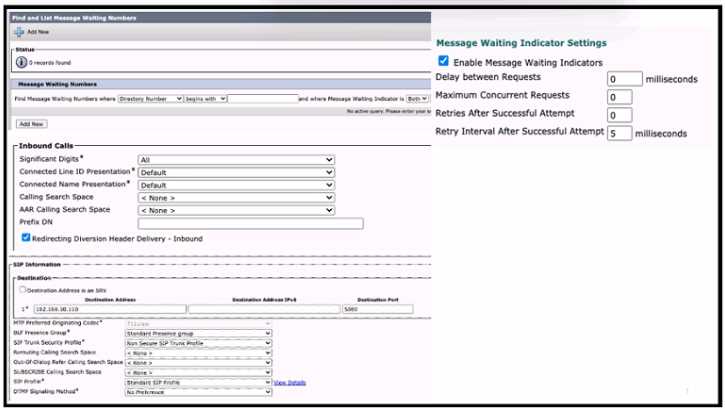
Refer to the exhibit A collaboration engineer is troubleshooting an issue with MWIs not working for
SIP-integrated Cisco Unity Connection users on Cisco UCM Calls to the Cisco Unity Connection work.
but MWIs do not light This problem affects all users on the system Which action resolves the issue?
The issue seems system-wide, so adjusting the Message Waiting Numbers (D) would fix the root cause instead of security or timers. D
Maybe C, since routing MWI might need proper calling search space on the SIP trunk.
version 10.x. The engineer has confirnæd that the server recovery manager service is configured
using system defaults. The engineer notices that user sessions have not fallen back to the homed
nodes. What is the cause this Issue?
D. The system typically requires the failed service or server to be stable for a certain period before sessions can fail back. If the recovery hasn’t reached that 30-minute threshold, the fallback won’t trigger automatically. This prevents flapping or unstable failover situations. So even if everything looks good, you might just need to wait a bit longer before seeing sessions move back.
Makes sense that fallback needs manual trigger, so A.
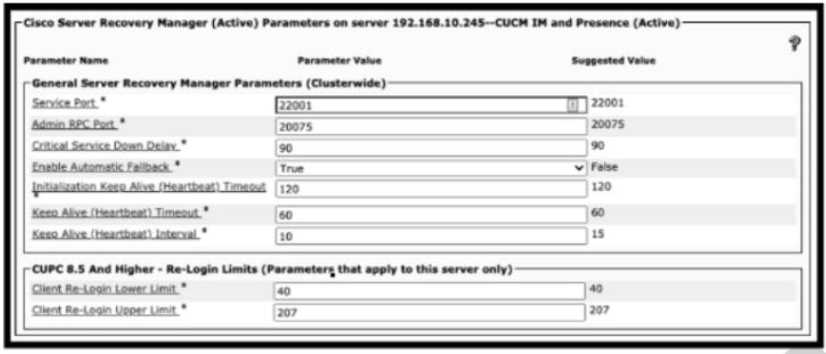
Refer to the exhibit. A collaboration engineer restored a failed primary node of an active/standby IM
and presence subcluster. The engineer notices that users fallback to the node occurred. Which action
resolves this issue?
Not A, rebooting might not fix the fallback since the system probably requires a stable uptime period after restoration. Waiting 30 minutes as in B allows the node to fully synchronize and regain user trust.
A/D? Rebooting might clear lingering issues on the primary node, while adjusting the heartbeat interval could help maintain the connection and prevent fallback. Both seem plausible depending on what’s causing the fallback.

Refer to the exhibit. An administrator is configuring a Cisco Unity Express call handier. One of the
options will transfer calls off-system to Cisco UCME. The administrator wants the transfer to finish
while the transfer target Is ringing. Which transfer-mode command completes the configuration?
Another point is that attended transfers usually require the transferor to stay on the call until the target answers, so A doesn’t fit. D seems unrelated or a typo, so B or C are left, but B makes more sense for immediate transfer.
B. Blind refer fits because the transfer happens immediately, letting the original call end while the target rings. Semi-attended would wait for the target to pick up first, so it’s less likely here.
new branch location report that 'cannot locate server is displayed when they launch the client When
the engineer manually configures the server settings on a client, the dient logs in successfully. The
Cisco IM and Presence servers are located across the WAN at the corporate HQ Which action
resolves the issue?
D imo, the key is that Jabber relies on the _cisco-uds_tcp SRV record for server discovery. If clients at the branch can login only after manual config, it suggests they can’t automatically locate the IM and Presence servers via DNS. Adding the _cisco-uds_tcp SRV record to the branch DNS would help clients find the service without needing manual setup. Options A and B don’t address discovery directly, and C’s _collab-edge record is more for Expressway or external edge services, not internal IM&P server location.
C imo. The issue sounds like Jabber can’t automatically find the server, and adding the _collab-edge SRV record usually helps clients locate the Cisco Collaboration Edge services, especially from remote sites. Since manual config works, it means DNS-based auto-discovery is broken. D could be relevant but _cisco-uds is more for Unified Directory Services, which feels less related here. The core problem is the client can’t find the server via DNS, so fixing that with the right SRV record (C) seems the way to go.
wants to complete a silent installation of the client clear any existing bootstrap file, and use a Service
Domain of cisco com Which install command achieves these goals?

Maybe A, since it clearly has the flag to clear the bootstrap file along with silent install and setting the service domain. The other options either don’t explicitly clear the bootstrap or are missing parts of the command needed for a full silent install with those settings. That explicit clearing is key here, so A stands out for me.
A/D? Both have the silent install with /quiet and specify the service domain. A explicitly uses the flag to clear the bootstrap file, while D seems to handle it too but less clearly. Since clearing the bootstrap is a must, A feels safer, but D could work if its switch covers that implicitly. I’d pick A just because it spells out clearing the bootstrap, which seems crucial here.
assistance. The Cisco TAC Engineer indicates that diagnostic information has not been received for
the cluster. Which action resolves this issue?
Maybe A could work since manually downloading logs might bypass the automatic upload issue. If diagnostics aren’t coming through, grabbing logs directly could help TAC troubleshoot.
Option D, because enabling that setting directly allows diagnostics to be sent automatically.
service is required tor the administrator to achieve Digital Networking between the clusters?
Maybe A, since an agent usually does the hands-on syncing work, which is what you’d need to keep multiple clusters connected and updated in real time. Services might just be broader management layers.
Maybe C, since a "Replication Service" sounds like it would handle ongoing syncing between clusters, which is crucial for digital networking. Agents might just be smaller parts or helpers.
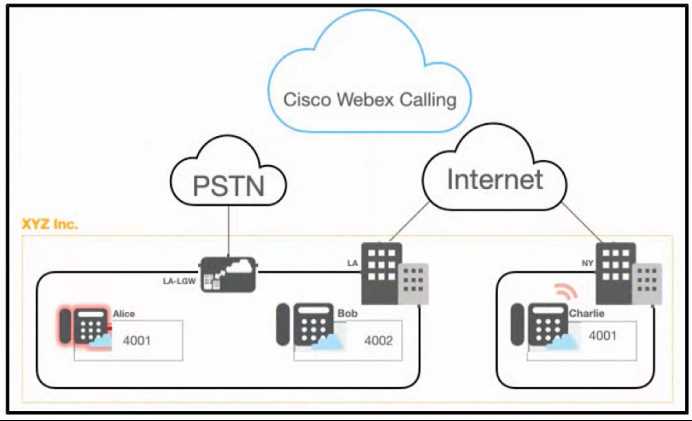
A company deployed the Cisco Webex calling with Cisco Unified Border Element as a local gateway
for PSTN calls and a firewall to restrict and control the HTTP-based traffic that leaves and enters the
network. However, Alice in LA cannot dial 82024001 to reach Charlie in NY. Which action must an
administrator take to resolve the issue?
It’s B, since SIP signaling uses TCP 5062 which must be allowed outbound.
B Opening TCP port 5062 outbound on the firewall is key because CUBE mostly uses TCP for SIP signaling, not UDP. Without that port open, calls won’t get through the firewall, blocking dialing like Alice’s situation. The UDP ports usually handle media streams, but if signaling can’t pass, the call can’t even start, so opening TCP 5062 is the right move here.
enabled PC? (Choose two.)
B, D. The cloud-based options (C and E) don’t really count since the question asks about on-prem deployments for Windows PCs. Contact Center Agent (A) feels more like a user role than a standalone deployment type, so it’s unlikely to be one of the two. B (IM-only) and D (Full UC) line up with what Cisco typically offers for on-prem Windows installs. It’s pretty clear that these are the actual deployment types Cisco supports locally on Windows machines.
Option B and D for sure, cloud options don’t run on-prem Windows PCs.