Free Cisco 300-810 Actual Exam Questions - Question 1 Discussion
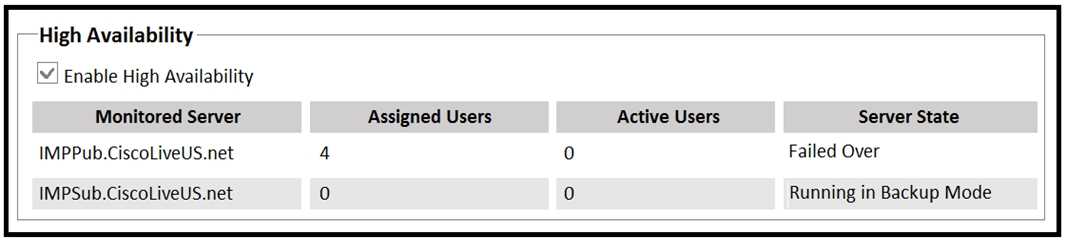
A customer reports that after a network failure, all of the Cisco Jabber clients are not switched back
to their home nodes. An engineer determines that the primary Cisco IM&P server is in Failed Over
state. Which two actions should be performed to bring the system back to operational state and to
prevent future occurrences? (Choose two.)
B imo, since making sure both servers are properly in the redundancy group is basic but crucial. D also fits because manually clicking Fallback is the direct way to recover from a failed over state without waiting for restarts.
Option C makes sense since restarting the primary server can trigger fallback if it’s stuck. Also, B seems important to double-check both servers are correctly set up in the redundancy group to avoid failover issues later.
I’m thinking B and D make the most sense here. If both servers aren’t correctly listed in the Presence Redundancy Group, failover might not work right. Then clicking Fallback (D) would bring the primary back to active. I’m less convinced about E since the question doesn’t say if Automatic Failover is off—it might already be enabled by default. A or C don’t really address the failover config or recovery process directly. Does anyone know if the Automatic Failover setting defaults to true or false in this setup?
It’s D and B for me. Clicking Fallback is needed to restore the primary role, and ensuring both servers are properly set in the redundancy group prevents config issues causing failover problems.
Option D for forcing fallback, plus E to automate future failbacks.
It’s D and E; fallback resets the server, and auto-failover stops future hangs.
D, E. The fallback button (D) seems like the direct way to force the primary IM&P server back from failed over state, which should restore normal service. Then setting the Automatic Failover parameter (E) to True should help the system handle future failures and recoveries automatically without manual intervention. This combo addresses both immediate recovery and prevention. Options like A don’t seem practical because having all users re-login isn’t scalable, and B feels more like a setup check rather than a fix. Restarting the server (C) might work but seems less controlled than using the pro
Is it clear if the fallback button (D) triggers automatic user re-login or just server switch?