Free Cisco 300-810 Actual Exam Questions - Question 8 Discussion
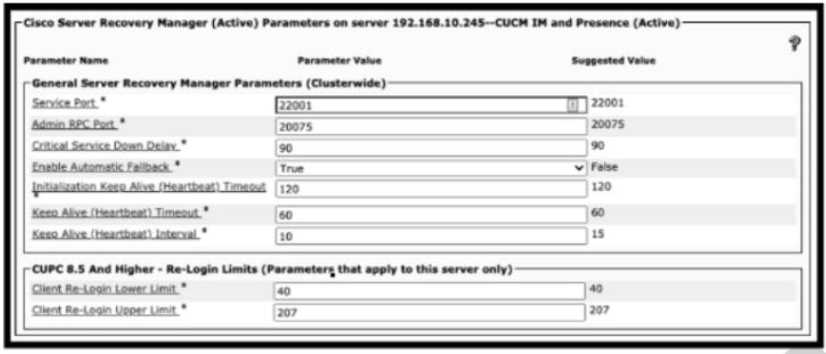
Refer to the exhibit. A collaboration engineer restored a failed primary node of an active/standby IM
and presence subcluster. The engineer notices that users fallback to the node occurred. Which action
resolves this issue?
Not A, rebooting might not fix the fallback since the system probably requires a stable uptime period after restoration. Waiting 30 minutes as in B allows the node to fully synchronize and regain user trust.
A/D? Rebooting might clear lingering issues on the primary node, while adjusting the heartbeat interval could help maintain the connection and prevent fallback. Both seem plausible depending on what’s causing the fallback.
Makes sense that the system needs some stability time after the node is restored, so B seems right here. Waiting 30 minutes uptime probably lets services sync properly before users stop falling back.
Option B mentions waiting 30 minutes of uptime for the primary node, but does it specify if this is after a failover or after restoration? Also, is there any info on current heartbeat settings or client re-login limits in the exhibit? Without those details, it’s hard to say if rebooting or modifying limits would help here. Wondering if the fallback is due to the node not being fully back online or some config that needs tweaking.