Free Microsoft Data Engineering DP-700 Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for DP-700 certification exam which are developed and validated by Microsoft subject domain experts certified in Microsoft Data Engineering DP-700 . These practice questions are update regularly as we keep an eye on any recent changes in DP-700 syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Microsoft Data Engineering DP-700 exam questions and pass your exam on first try.
In Workspace1, you create a new notebook named Notebook2.
You need to ensure that you can attach Notebook2 to the same Apache Spark session as Notebook1.
What should you do?
A. High concurrency is the only option that actually allows sharing the same Spark session among notebooks. The others are about resource management, not session sharing.
I’m with the folks saying A. High concurrency is the feature that actually lets multiple notebooks connect to the same Spark session, which is exactly what the question asks for. The other options just tweak performance or resource allocation but don’t enable session sharing between notebooks. So, A makes the most sense here.
requirements. What should you include in the recommendation?
It’s A. If the goal is to handle old files without just deleting, copying them somewhere else first makes sense. B and C are more about managing data inside a Delta Lake, so they’d only fit if that’s the format here. D is too final if we need to keep files around somehow. Since the question says “handling” old files but doesn’t confirm deletion, copying with a data pipeline covers archiving or moving without losing data.
If the goal is just to remove old files entirely, D seems straightforward since it deletes them. No extra steps like copying or optimizing needed if cleanup is the main focus. D
named DW1 that is modelled by using MD5 hash surrogate keys.
DW1 contains a single fact table that has grown from 200 million rows to 500 million rows during the
past year.
You have Microsoft Power BI reports that are based on Direct Lake. The reports show year-over-year
values.
Users report that the performance of some of the reports has degraded over time and some visuals
show errors.
You need to resolve the performance issues. The solution must meet the following requirements:
Provide the best query performance.
Minimize operational costs.
Which should you do?
It’s C, smaller keys cut storage and speed up joins without extra cost.
B vs C, increasing capacity might help speed but changing keys could reduce storage and improve performance more sustainably.
Which should you do?
Maybe A could work if the book reviews need complex transformations or real-time processing, but since that’s not specified, it feels a bit over the top. D seems more straightforward for just moving and processing data in batches, so I’m ruling out B and C since they don’t really address data processing. If the question was about just sharing data externally, C might fit, but it’s about implementing a solution, so D still makes the most sense here.
It’s D because a data pipeline handles batch processing well without extra complexity.
multiple sales representatives.
You plan to implement row-level security (RLS).
You need to ensure that the sales representatives can see only their respective data.
Which warehouse object do you require to implement RLS?
D. The key here is you need something that can dynamically filter rows based on who's querying, and functions are designed for that in row-level security setups. Constraints (B) are more about data integrity, not filtering access. Procedures (A) don't filter data on select queries, and schemas (C) are more about organizing objects, not controlling access at the row level. So the function is what actually applies the security logic per user.
D, since functions define the filtering logic needed for row-level security.
Workspace2.
The company decides to implement a domain strategy to organize the workspaces.
You need to ensure that a user can perform the following tasks:
Create a new domain for the sales department.
Create two subdomains: one for the east region and one for the west region.
Assign Workspace1 to the east region subdomain.
Assign Workspace2 to the west region subdomain.
The solution must follow the principle of least privilege.
Which role should you assign to the user?
C, since domain contributor covers creation without full admin rights, fitting least privilege.
Assigning workspaces to subdomains seems like a step beyond just creating them, so domain contributor might not cover it fully. Domain admin probably fits better for managing both creation and assignments while still scoped to domains.
You have a Fabric deployment pipeline named deployPipeline1 that deploys items from Workspace1
to Workspace2. DeployPipeline1 contains all the items in Workspace1.
You recently modified the items in Workspaces1.
The workspaces currently contain the items shown in the following table.
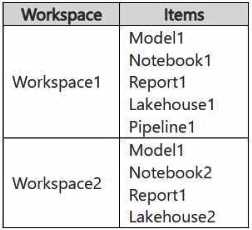
Items in Workspace1 that have the same name as items in Workspace2 are currently paired.
You need to ensure that the items in Workspace1 overwrite the corresponding items in Workspace2.
The solution must minimize effort.
What should you do?
A/C? Deleting or backing up first covers all bases if overwrite isn’t default.
It’s D because items paired by name usually get overwritten automatically during deployment.
Notebook1 reads data into a DataFrame from a table named Table1 and applies transformation logic.
The data from the DataFrame is then written to a new Delta table named Table2 by using a merge
operation.
You need to consolidate the underlying Parquet files in Table1.
Which command should you run?
If we think about the purpose of each option, VACUUM (A) mainly removes old files no longer needed, so it’s not really about consolidating files. BROADCAST (B) and CACHE (D) are about query performance, not file management. So, even if we don’t know for sure that Table1 is Delta, the only command focused on merging small files into bigger ones is OPTIMIZE (C). Does anyone know if Fabric enforces tables to be Delta by default? That could settle this clearly.
A/B? VACUUM (A) removes old files but doesn’t merge Parquet files, so probably not that. BROADCAST (B) has nothing to do with file consolidation; it’s for join optimization. OPTIMIZE (C) is specifically for merging small files in Delta tables, which sounds exactly like what’s needed here. CACHE (D) just puts data in memory, not physical file consolidation. So between those, C still seems the way to go given the goal is consolidation of Parquet files.
lakehouse named Lakehouse1, a data pipeline, a notebook, and several Microsoft Power BI reports.
A user named User1 wants to use SQL to analyze the data in Lakehouse1.
You need to configure access for User1. The solution must meet the following requirements:
Provide User1 with read access to the table data in Lakehouse1.
Prevent User1 from using Apache Spark to query the underlying files in Lakehouse1.
Prevent User1 from accessing other items in Workspace1.
What should you do?
It’s A because direct sharing with read access via SQL endpoint limits User1 to just query data without broader workspace or Spark permissions, keeping the access tightly scoped as required.
It’s A because sharing Lakehouse1 directly with SQL read access avoids workspace roles that expose other items or Spark capabilities. This keeps User1’s access narrow and secure.
HOTSPOT You plan to process the following three datasets by using Fabric: • Dataset1: This dataset will be added to Fabric and will have a unique primary key between the source and the destination. The unique primary key will be an integer and will start from 1 and have an increment of 1. • Dataset2: This dataset contains semi-structured data that uses bulk data transfer. The dataset must be handled in one process between the source and the destination. The data transformation process will include the use of custom visuals to understand and work with the dataset in development mode. • Dataset3. This dataset is in a takehouse. The data will be bulk loaded. The data transformation process will include row-based windowing functions during the loading process. You need to identify which type of item to use for the datasets. The solution must minimize development effort and use built-in functionality, when possible. What should you identify for each dataset? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 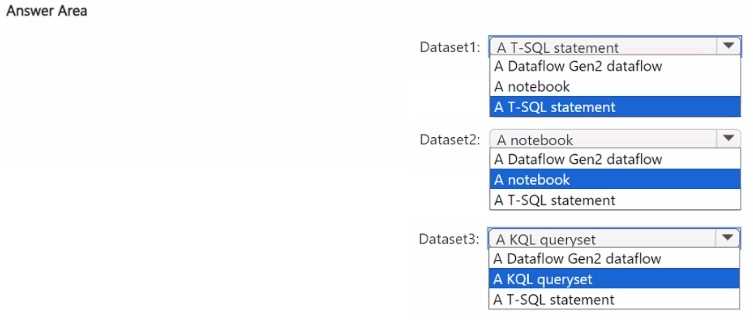
Dataset1 fits relational table since it has a neat integer key and simple structure.
For Dataset1, the unique integer key and simple incremental nature work well with a relational table, making development straightforward. Dataset2’s semi-structured data and bulk transfer combined with custom visuals suggest a lake database, since it handles unstructured data and supports those visuals better. Dataset3’s bulk load and use of row-based window functions definitely call for a data warehouse item, which optimizes those analytic operations during loading. This setup uses built-in capabilities efficiently without overcomplicating the process.
HOTSPOT You have a Fabric warehouse named DW1 that contains four staging tables named ProductCategory, ProductSubcategory, Product, and SalesOrder. ProductCategory, ProductSubcategory, and Product are used often in analytical queries. You need to implement a star schema for DW1. The solution must minimize development effort. Which design approach should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 
I’m thinking option D makes sense to combine ProductCategory and ProductSubcategory into a single dimension since those are closely related hierarchies. It cuts down on the number of joins and fits the star schema approach. For the fact table, A is the obvious choice since SalesOrder contains transactional data with measures. This way, you keep the design simple and efficient without extra development work. The other options don’t really group the dimension tables well or miss the clear fact table candidate.
I see why A for SalesOrder as the fact table works since it has the measures. For dimensions, D is good because it combines those related tables into one, cutting down on joins and complexity.
HOTSPOT You have a Fabric workspace named Workspace1 that contains the items shown in the following table. 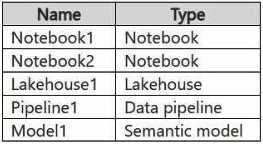 For Model1, the Keep your Direct Lake data up to date option is disabled. You need to configure the execution of the items to meet the following requirements: Notebook1 must execute every weekday at 8:00 AM. Notebook2 must execute when a file is saved to an Azure Blob Storage container. Model1 must refresh when Notebook1 has executed successfully. How should you orchestrate each item? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
For Model1, the Keep your Direct Lake data up to date option is disabled. You need to configure the execution of the items to meet the following requirements: Notebook1 must execute every weekday at 8:00 AM. Notebook2 must execute when a file is saved to an Azure Blob Storage container. Model1 must refresh when Notebook1 has executed successfully. How should you orchestrate each item? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 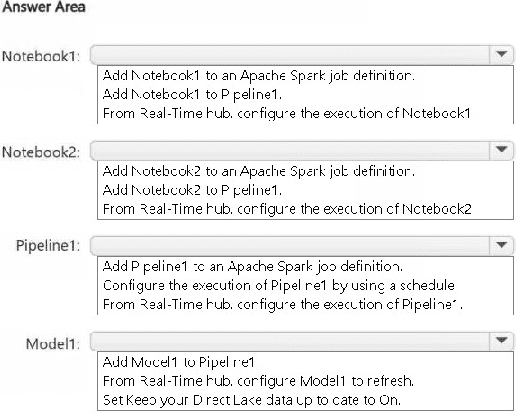
For Notebook1, scheduling it at 8 AM weekdays makes sense. Notebook2 should use the event trigger tied to the blob save. Model1 refresh looks like it needs a dependent trigger after Notebook1 runs successfully.
I agree with scheduling Notebook1 and event-triggering Notebook2; Model1 refresh depends on Notebook1’s success.
HOTSPOT You are building a data loading pattern for Fabric notebook workloads. You have the following code segment:  For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. 
I also think the batch processing angle is strong here since checkpointing usually isn’t part of streaming setups. Plus, the code doesn’t show any triggers or listeners that’d indicate real-time data flow, so No for streaming feels right. On schema updates, there’s no explicit handling in the snippet, so that’s another No from me. The focus seems more on loading and saving states rather than evolving schemas or real-time ingestion.
I’m saying No for real-time streaming because the code looks like it’s designed for batch uploads with checkpoints, not continuous data streams. Also, No on automatic schema evolution since there’s no schema update logic shown.
HOTSPOT You are building a data orchestration pattern by using a Fabric data pipeline named Dynamic Data Copy as shown in the exhibit. (Click the Exhibit tab.) 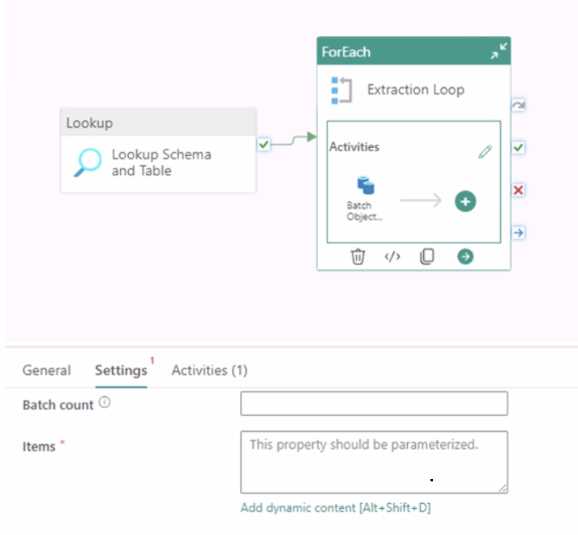 Dynamic Data Copy does NOT use parametrization. You need to configure the ForEach activity to receive the list of tables to be copied. How should you complete the pipeline expression? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Dynamic Data Copy does NOT use parametrization. You need to configure the ForEach activity to receive the list of tables to be copied. How should you complete the pipeline expression? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 
I agree using @variables('tables') fits best here since no parameters are allowed. Just make sure the variable is initialized beforehand, or ForEach won’t have any tables to iterate over.
Using @variables('tables') fits since no params allowed; just ensure variable’s set first.
HOTSPOT You have a Fabric workspace that contains a warehouse named Warehouse!. Warehousel contains a table named DimCustomers. DimCustomers contains the following columns: • CustomerName • CustomerlD • BirthDate • Email You need to configure security to meet the following requirements: • BirthDate in DimCustomer must be masked and display 1900-01-01. • Email in DimCustomer must be masked and display only the first leading character and the last five characters. How should you complete the statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 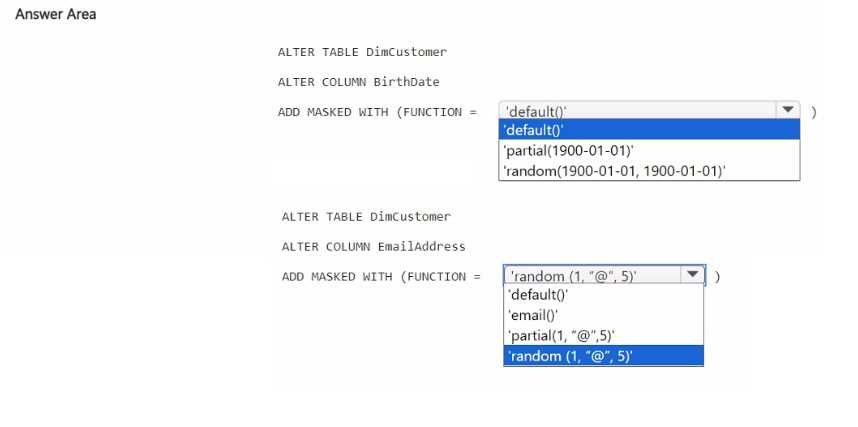
For BirthDate, Default mask is the go-to since it replaces the whole date with 1900-01-01. For Email, Partial mask works because it can reveal specific characters upfront and at the end, matching the requirement closely.
For BirthDate, the Default mask fits perfectly since it can replace the entire value with a fixed date like 1900-01-01, matching the requirement exactly. For Email, Partial mask seems right because it can reveal parts of the string, but I'm not sure if it allows showing exactly one leading and five trailing characters or if it’s more limited to something like first and last characters only. Still, other masking options don’t give that kind of partial reveal, so Partial is the best fit here despite the exact parameter question.