Free Microsoft Data Engineering DP-700 Actual Exam Questions - Question 10 Discussion
HOTSPOT You plan to process the following three datasets by using Fabric: • Dataset1: This dataset will be added to Fabric and will have a unique primary key between the source and the destination. The unique primary key will be an integer and will start from 1 and have an increment of 1. • Dataset2: This dataset contains semi-structured data that uses bulk data transfer. The dataset must be handled in one process between the source and the destination. The data transformation process will include the use of custom visuals to understand and work with the dataset in development mode. • Dataset3. This dataset is in a takehouse. The data will be bulk loaded. The data transformation process will include row-based windowing functions during the loading process. You need to identify which type of item to use for the datasets. The solution must minimize development effort and use built-in functionality, when possible. What should you identify for each dataset? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 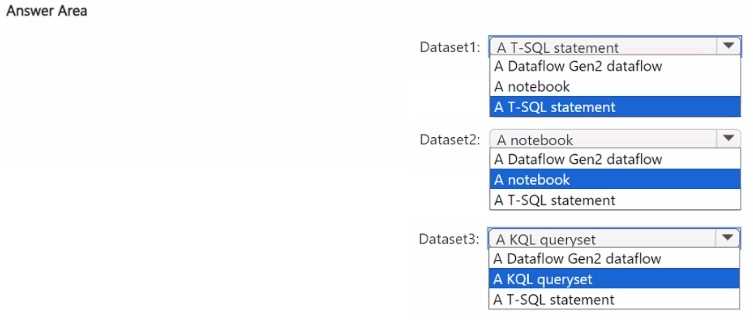
Dataset1 fits relational table since it has a neat integer key and simple structure.
For Dataset1, the unique integer key and simple incremental nature work well with a relational table, making development straightforward. Dataset2’s semi-structured data and bulk transfer combined with custom visuals suggest a lake database, since it handles unstructured data and supports those visuals better. Dataset3’s bulk load and use of row-based window functions definitely call for a data warehouse item, which optimizes those analytic operations during loading. This setup uses built-in capabilities efficiently without overcomplicating the process.
For Dataset1, a relational table fits best because of the straightforward primary key. Dataset2’s semi-structured format and custom visuals lean toward a lake database. Dataset3 needs row-based windowing, so data warehouse is the way to go.
Dataset1 fits a relational table since it has a clean, incremental integer key. Dataset2’s semi-structured bulk data and need for custom visuals point to a lake database item. Dataset3, with window functions during bulk load, suits a data warehouse.
For Dataset1, a relational table makes sense given the unique integer key. Dataset2’s need for semi-structured bulk data and custom visuals points to a lake database. Dataset3 should be a data warehouse item for the row-based window functions during bulk load.
For Dataset1, a relational table seems the best pick since it has a unique integer primary key and direct incremental values. It fits the structured, row-based data model perfectly. Dataset3 clearly aligns with a data warehouse item because of the bulk load and use of windowing functions, which are typical in warehouse scenarios. Dataset2 is tricky but since it involves semi-structured data and bulk transfer handled in one process, plus custom visuals only for development mode, a lake database seems appropriate. It supports semi-structured data well and allows flexible transformations without
For Dataset1, a relational table fits since it has a unique integer key starting at 1. Dataset3 is best as a data warehouse item due to bulk loading and row-based window functions. Dataset2 seems like a lake database given the semi-structured bulk data and dev-time visuals.
Dataset1 looks like a relational table, Dataset2 fits lake database, Dataset3 suits data warehouse.
Datasets 1 and 3 are clearly tables, only Dataset2 fits a lake database scenario.
This one seems pretty straightforward. For Dataset1, a relational table should work since it has a unique integer key. Dataset2 might fit best with a lake database for semi-structured bulk data and custom visuals. Dataset3’s bulk load with window functions looks like a dedicated warehouse table.