Free Microsoft Azure DP-300 Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for DP-300 certification exam which are developed and validated by Microsoft subject domain experts certified in Microsoft Azure DP-300 . These practice questions are update regularly as we keep an eye on any recent changes in DP-300 syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Microsoft Azure DP-300 exam questions and pass your exam on first try.
HOTSPOT You have an Azure SQL managed instance. You need to restore a database named DB1 by using Transact-SQL. Which command should you run? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 
B works since RESTORE isn’t supported on managed instances anyway.
I’d pick option B as well. Since managed instances don’t support RESTORE like on regular SQL Server, the way to restore is by creating a new database as a copy of a backup or existing database. The CREATE DATABASE AS COPY OF syntax fits this scenario perfectly because it’s designed for managed instances, letting you basically clone the DB without needing RESTORE commands. Definitely not A or C since those use RESTORE which isn’t supported here.
will also support Scala and SQL.
Which switch should you use to switch between languages?
B Using % is the standard way to switch languages in a Databricks notebook, like %r for R or %sql for SQL. The other options don’t match how Databricks handles multi-language cells.
Probably B here too since % is used as a magic command prefix to switch between languages, which matches the question about R, Scala, and SQL in one notebook.
HOTSPOT You configure backup for an Azure SQL database as shown in the following exhibit. 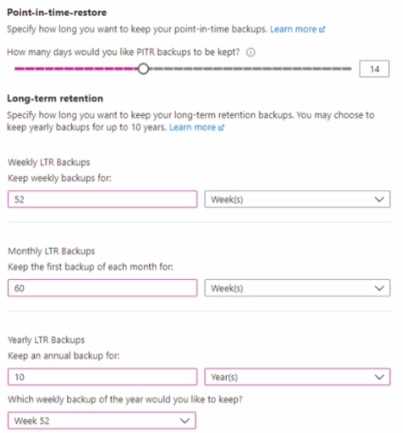 Use the drop-down menus to select the answer choice the completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.
Use the drop-down menus to select the answer choice the completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. 
Geo-redundant is obvious, and 7 days looks like a default retention period.
Looks like the backup redundancy is Geo-redundant for sure from the image.
You have an Azure SQL database named DBI that contains a nonclustered index named index1. End users report slow queries when they use index1. You need to identify the operations that are being performed on the index. Which dynamic management view should you use? 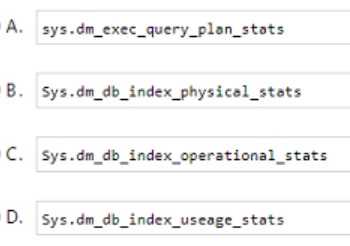
Maybe D, since it might give stats on how queries are interacting with the index during execution. C seems focused on locks, but D could show actual operations causing delays.
Good point on C showing detailed operational data. I’d add B isn’t enough since it just tracks how often indexes are used, not what’s happening during queries. C is the only one with in-depth lock and latch info, so C.
HOTSPOT You need to implement the monitoring of SalesSQLDb1. The solution must meet the technical requirements. How should you collect and stream metrics? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 
I think using Azure Monitor makes sense since it directly supports SQL DB metrics collection. For streaming, if the question doesn’t say anything about transforming or analyzing the data on the fly, Event Hubs alone should be enough to just capture and stream the metrics as they come. Stream Analytics seems like overkill here unless there’s a clear need for real-time querying or filtering before sending the data downstream. So Azure Monitor plus Event Hubs feels like the simplest, most fitting combo.
Azure Monitor is the go-to for SQL DB metrics. For streaming, Event Hubs fits since it handles large data streams without added processing, unlike Stream Analytics which is more for real-time query needs.
HOTSPOT You have an Azure subscription that contains a storage account named databasebackups. You have an Azure SQL managed instance named DB1. You need to back up DB1 to databasebackups. How should you complete the commands? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 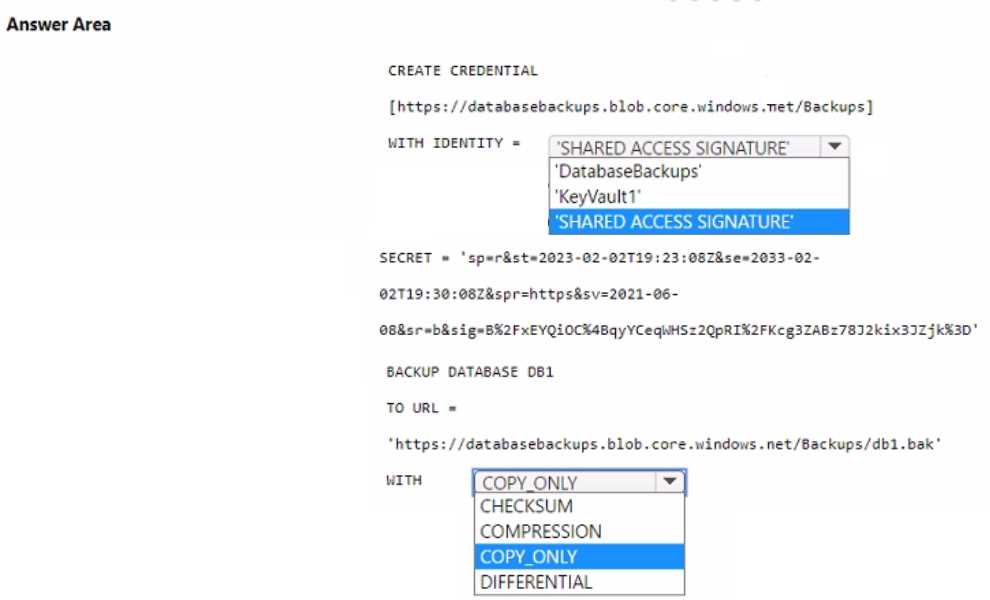
Are we assuming the storage account is general-purpose v2 or Blob Storage?
You have a database named DB1 that is NOT in the availability group.
You create a full database backup of DB1.
You need to add DB1 to the availability group.
Which restore option should you use on the secondary replica?
B, because the secondary replica needs the database in a restoring state to join the AG.
Option B but this question feels kinda vague, anyone else?
named df1.
DF1 contains a linked service.
You have an Azure Key vault named vault1 that contains an encryption kay named key1.
You need to encrypt df1 by using key1.
What should you do first?
A imo, because you usually disable purge protection before changing keys for encryption.
It’s D
SIMULATION Task 1 In an Azure SQL database named db1, you need to enable page compression on the PK_SalesOrderHeader_SalesOrderlD clustered index of the SalesLT.SalesOrderHeader table.
D, since compression targets indexes directly, not the entire table here.
I think C can be ruled out because it talks about altering the table with a data compression option, which might not apply here. D makes more sense since we’re focusing on the clustered index itself.
DRAG DROP You have an Azure SQL managed instance named SQLMI1 that has Resource Governor enabled and is used by two apps named App1 and App2. You need to configure SQLMI1 to limit the CPU and memory resources that can be allocated to App1. Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. 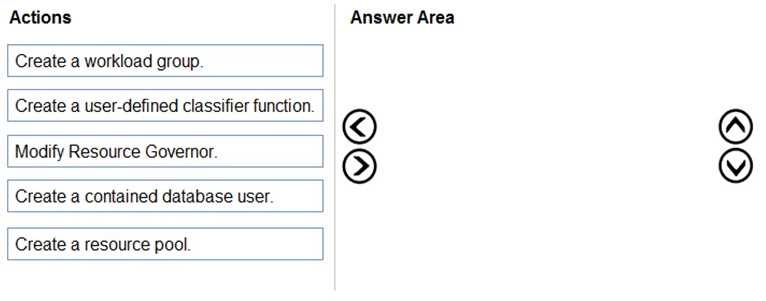
Start with creating the resource pool to set limits, then workload group, classifier function, and enable Resource Governor.
I think the key is recognizing that you first define the resource pool with the CPU and memory caps. Next, you create a workload group tied to that pool to manage session allocation. Then, the classifier function comes in, which checks incoming sessions (like from App1) and routes them to the right workload group based on conditions like app name. Finally, enabling Resource Governor applies all these settings. The step order matters because you can't classify sessions without having groups and pools set up first.
HOTSPOT You have an Azure SQL database. You are reviewing a slow performing query as shown in the following exhibit. 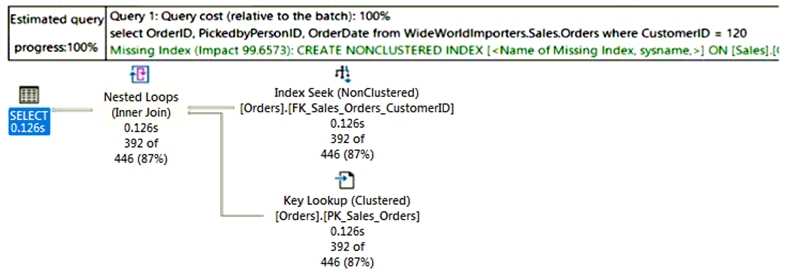 Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. 
I’m with those saying the scan points to a missing index on OrderDate alone. Adding other columns might help, but the biggest gain is from eliminating that scan first. Also, the sort looks like a Top N Sort since it’s just taking the first few results after ordering. If we fix the scan, the sort will become cheaper too. So picking B for the missing index and A for the sort type makes sense here.
The query’s slow because it’s doing a scan, so the right missing index is probably on OrderDate alone (B). The sort operation is likely a Top N Sort (A) since it’s limiting results. That fits the plan shape.
SIMULATION Task 8 You plan to perform performance testing of db1. You need prevent db1 from reverting to the last known good query plan.
If the test is on SQL Server, disabling automatic plan correction might involve trace flags or certain database scoped configurations, so options mentioning those could be right. Otherwise, options about Oracle or MySQL won’t apply.
I’d rule out any options that mention “last known good plan” caching or forcing a plan freeze. Usually, you want to disable plan freezing or anything like automatic plan correction to stop it from reverting. One trap could be picking something that only updates stats but doesn’t prevent reversion. The key is to look for the setting or command that keeps the optimizer from switching back automatically during your test.
DRAG DROP Your company analyzes images from security cameras and sends alerts to security teams that respond to unusual activity. The solution uses Azure Databricks. You need to send Apache Spark level events, Spark Structured Streaming metrics, and application metrics to Azure Monitor. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions in the answer area and arrange them in the correct order. 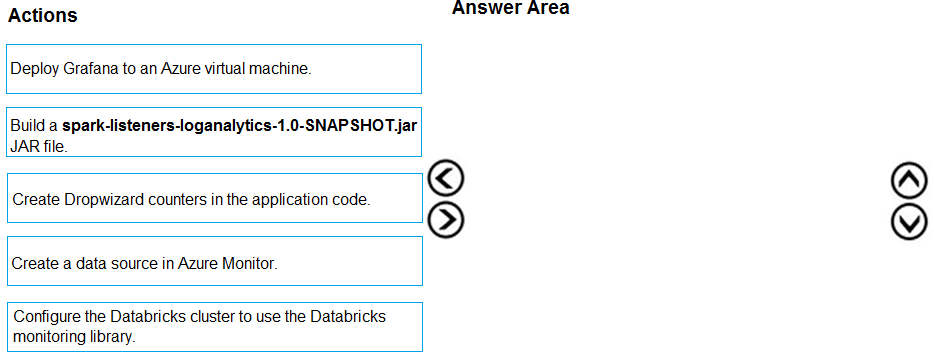
Agree, start with cluster diagnostic logs, then streaming metrics, finally send to Azure Monitor.
First thing’s to enable diagnostic settings on the cluster to catch Spark events. After that, configure Structured Streaming metrics tracking, and lastly, send all those logs and metrics to Azure Monitor.
HOTSPOT You have an Azure SQL database named DB1. The automatic tuning options for DB1 are configured as shown in the following exhibit. 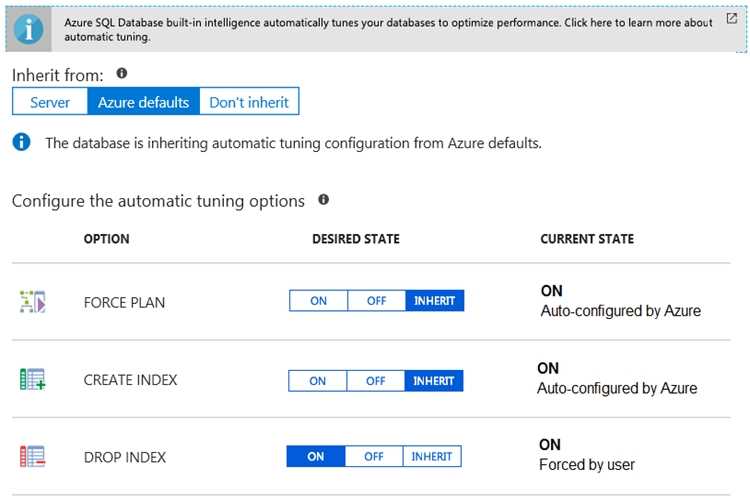 For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. 
I agree with saying No for forced plan since it’s off in the config. Also, the statement about automatic index creation and dropping should be Yes because they’re clearly enabled. The question is pretty straightforward if you just focus on what’s toggled on or off in the settings shown. The confusion probably comes from mixing up current versus recommended states, but from what I see here, it’s definitely the current settings, so trust those for your answers.
I’d say No for the forced plan statement because it’s set to off in the current config. So even if a regression is detected, it won’t automatically force a plan. The other tuning options are clearly enabled though.
DRAG DROP You plan to create a table in an Azure Synapse Analytics dedicated SQL pool. Data in the table will be retained for five years. Once a year, data that is older than five years will be deleted. You need to ensure that the data is distributed evenly across partitions. The solutions must minimize the amount of time required to delete old data. How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. 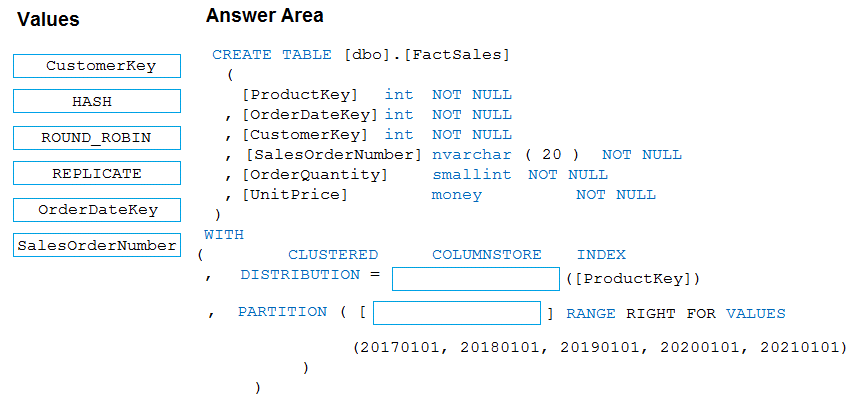
I think option D for PARTITION BY makes sense since yearly partitions help delete old data fast by dropping partitions. For DISTRIBUTION, C looks better because HASH on a key like CustomerID spreads data evenly.
Is there any info on the expected volume of data or how often queries will filter on date? That could affect the choice between hash and range distribution here.