Free AWS MLA-C01 Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for MLA-C01 certification exam which are developed and validated by Amazon – AWS subject domain experts certified in AWS MLA-C01 . These practice questions are update regularly as we keep an eye on any recent changes in MLA-C01 syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our AWS MLA-C01 exam questions and pass your exam on first try.
using the Amazon SageMaker linear learner built-in algorithm with a value of multiclass_dassifier for
the predictorjype hyperparameter.
What should the company do to MINIMIZE false positives?
Probably C. Increasing target_precision is the only option directly tied to reducing false positives since precision measures how many predicted positives are actually correct. A and B don’t really impact false positive rates directly, just model complexity or training time. D makes no sense because switching to a regressor won’t help with classification errors like false positives. The question is about minimizing false positives, and focusing on precision is the most straightforward way.
C imo, since increasing target_precision directly reduces false positives by emphasizing precision.
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3. The dataset has a class imbalance that affects the learning of the model's algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data. The ML engineer needs to use an Amazon SageMaker built-in algorithm to train the model. Which algorithm should the ML engineer use to meet this requirement?
Guessing A, LightGBM handles imbalanced data and complex feature interactions nicely.
Good point about clustering and topic modeling being off for fraud detection, so A it is.
Which metric should the ML engineer use to evaluate the model's performance?
D. Since predicting prices is a regression task, classification metrics like accuracy or F1 don't apply. MAE gives a clear average error magnitude, making it the most suitable here.
D. Since this is about predicting apartment prices, which is a continuous value, you want a regression metric. Accuracy, AUC, and F1 are for classification tasks, so they’re not relevant here. MAE is straightforward—it tells you the average absolute difference between predicted and actual prices, which makes the model’s performance easier to interpret in real-world terms.
MB Apache Parquet data file to build a fraud detection model. The file includes several correlated
columns that are not required.
What should the ML engineer do to drop the unnecessary columns in the file with the LEAST effort?
Option C seems simpler here since it avoids extra setup like Spark or local downloads, and you can quickly write a small script to drop columns using SageMaker processing.
C, since it avoids setting up Spark or local downloads and is simpler than EMR.
company needs to implement a solution to automatically rotate the API tokens every 3 months.
Which solution will meet this requirement?
A, because Secrets Manager handles rotation natively, unlike KMS options here.
A imo, because Secrets Manager is built for secret rotation with built-in Lambda support, making it easier to automate token updates safely every 3 months. Parameter Store isn’t as specialized for rotation.
stored in Amazon S3 and is complex in structure. The ML engineer must use a file format that
minimizes processing time for the data.
Which file format will meet these requirements?
Parquet files are definitely optimized for complex data and fast processing, so D still makes sense here. CSV and JSON just don’t handle complexity or speed as well. D
A vs D? Parquet usually beats CSV for complex data, but codec support might mess things up.
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a central model registry, model deployment, and model monitoring. The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3. The company needs to run an on-demand workflow to monitor bias drift for models that are deployed to real-time endpoints from the application. Which action will meet this requirement?
A/B? A sounds solid since SageMaker Clarify is built for bias detection and can run on demand, which matches the requirement well. But B might still work if you want more control by pulling the model-monitor-analyzer image and running custom checks via Lambda. The question asks for on-demand bias drift monitoring, so both have merits, but Clarify feels more straightforward for this use case.
Maybe B since pulling the built-in analyzer image lets you customize bias checks flexibly.
structured data and unstructured dat
a. The company's ML engineers are assigned to specific advertisement campaigns.
The ML engineers must interact with the data through Amazon Athena and by browsing the data
directly in an Amazon S3 bucket. The ML engineers must have access to only the resources that are
specific to their assigned advertisement campaigns.
Which solution will meet these requirements in the MOST operationally efficient way?
Adeel M.: A imo—IAM policies on Glue catalog directly control Athena queries without extra S3 policy complexity.
It’s C—Lake Formation handles both S3 and Athena access in one place efficiently.
HOTSPOT An ML engineer is working on an ML model to predict the prices of similarly sized homes. The model will base predictions on several features The ML engineer will use the following feature engineering techniques to estimate the prices of the homes: • Feature splitting • Logarithmic transformation • One-hot encoding • Standardized distribution Select the correct feature engineering techniques for the following list of features. Each feature engineering technique should be selected one time or not at all (Select three.) 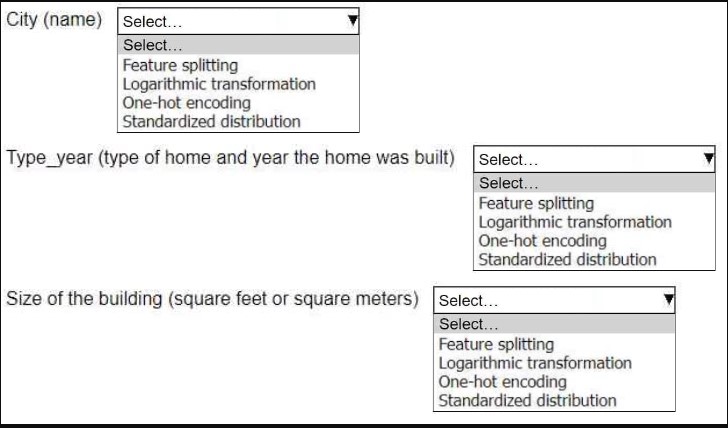
Feature splitting doesn’t seem necessary here since no combined features are mentioned. One-hot encoding fits well for categorical variables, and standardization is good for numeric features with a normal distribution.
I think feature splitting can be ruled out since there’s no mention of combined features like “city-state” or something that needs breaking apart. One-hot encoding is a no-brainer for categorical data like neighborhood or style of house, because numeric models don’t handle categories well. For numeric features, if they're roughly normal, standardization works best, but if the distribution is skewed (like price or area), applying a log transform helps normalize it before feeding into the model. So, the three techniques should be one-hot encoding, log transform, and standardization.
An ML engineer is building a generative AI application on Amazon Bedrock by using large language
models (LLMs).
Select the correct generative AI term from the following list for each description. Each term should
be selected one time or not at all. (Select three.)
• Embedding
• Retrieval Augmented Generation (RAG)
• Temperature
• Token
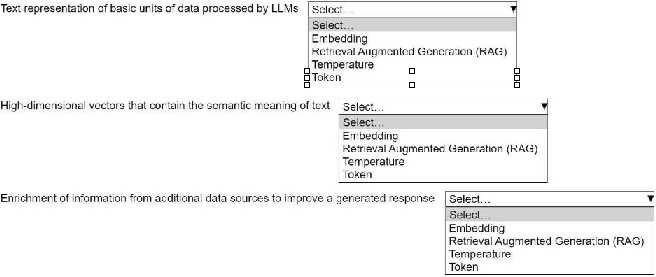
Embedding, RAG, and Temperature fit best since Token is basic input unit.
Embedding, RAG, and Temperature cover more specific generative AI roles than Token.
HOTSPOT An ML engineer needs to use Amazon SageMaker Feature Store to create and manage features to train a model. Select and order the steps from the following list to create and use the features in Feature Store. Each step should be selected one time. (Select and order three.) • Access the store to build datasets for training. • Create a feature group. • Ingest the records. 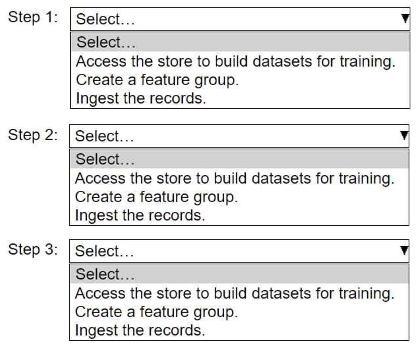
Starting with creating the feature group (B) is essential since it defines the schema. Then ingesting records (C) populates the store, and finally accessing the store (A) lets you build datasets for training.
Starting with creating the feature group sets up the schema and storage. Next, ingesting records fills it with data. Finally, accessing the store lets you build training datasets from those features.
HOTSPOT A company stores historical data in .csv files in Amazon S3. Only some of the rows and columns in the .csv files are populated. The columns are not labeled. An ML engineer needs to prepare and store the data so that the company can use the data to train ML models. Select and order the correct steps from the following list to perform this task. Each step should be selected one time or not at all. (Select and order three.) • Create an Amazon SageMaker batch transform job for data cleaning and feature engineering. • Store the resulting data back in Amazon S3. • Use Amazon Athena to infer the schemas and available columns. • Use AWS Glue crawlers to infer the schemas and available columns. • Use AWS Glue DataBrew for data cleaning and feature engineering. 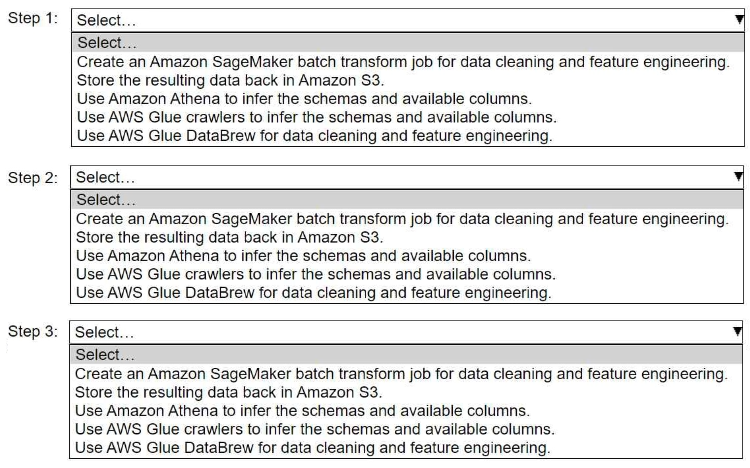
I’m thinking AWS Glue crawlers (D) should come first to detect any schema info despite no headers, since Athena usually relies on some metadata or headers to infer columns. After that, DataBrew (E) seems like the best move to clean and engineer features visually without coding. Finally, storing the cleaned data back in S3 (B) wraps it up. The batch transform job feels more like model inference than prepping raw unlabeled data. This order makes sense for a smooth pipeline from raw to ready-for-ML data.
I’d go with using AWS Glue crawlers (D) first, even without headers, since they can still detect schema patterns. Then use DataBrew (E) to clean and engineer features because it’s designed for that kind of task on raw data. Finally, store the cleaned dataset back in S3 (B) so it’s ready for model training. Batch transform feels more like a later step after you have clean, labeled data, not for initial prep. Athena is more for querying directly, less about preparing or cleaning the data itself.
HOTSPOT A company wants to host an ML model on Amazon SageMaker. An ML engineer is configuring a continuous integration and continuous delivery (Cl/CD) pipeline in AWS CodePipeline to deploy the model. The pipeline must run automatically when new training data for the model is uploaded to an Amazon S3 bucket. Select and order the pipeline's correct steps from the following list. Each step should be selected one time or not at all. (Select and order three.) • An S3 event notification invokes the pipeline when new data is uploaded. • S3 Lifecycle rule invokes the pipeline when new data is uploaded. • SageMaker retrains the model by using the data in the S3 bucket. • The pipeline deploys the model to a SageMaker endpoint. • The pipeline deploys the model to SageMaker Model Registry. 
The pipeline should start with the S3 event notification to trigger it, then SageMaker retrains the model using the new data, and finally, it deploys the updated model to the SageMaker endpoint for real-time use.
S3 event notification is definitely the trigger, so that removes the lifecycle rule option. After retraining, deploying to Model Registry makes sense before endpoint deployment, but since only three steps are allowed, I’d pick S3 event, retrain, then deploy to Model Registry.
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a central model registry, model deployment, and model monitoring. The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3. The company needs to use the central model registry to manage different versions of models in the application. Which action will meet this requirement with the LEAST operational overhead?
C imo, model groups in SageMaker Model Registry are designed to organize models and versions efficiently, which cuts down on manual tracking and operational work compared to just tagging versions.
Maybe D makes more sense here. The question emphasizes versioning within a central registry, and using unique tags for each version is straightforward without adding complexity from managing model groups. Model groups are good for big catalogs, but if the setup is simpler, tagging alone might keep things leaner. Plus, both C and D use SageMaker Model Registry, so the core requirement is met either way, but D could minimize overhead by avoiding extra organization layers.
delivers cleaned and prepared data to the company's Amazon S3 bucket every 3-4 days.
The company has an Amazon SageMaker pipeline to retrain the model. An ML engineer needs to
implement a solution to run the pipeline when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
Makes sense to skip polling since it's inefficient. C should be the easiest — EventBridge triggers right on the upload event, so no extra Lambda or Airflow setup needed. Definitely less to maintain overall. C
Probably C here. EventBridge can listen for S3 object-created events and trigger the SageMaker pipeline directly, so you avoid any extra Lambda functions or complicated orchestration setups. That’s less work to manage over time. A and D sound like overkill since Lifecycle rules aren’t meant to trigger training and MWAA is more for complex workflows, not simple event triggers. B works but has more overhead with the Lambda polling or scanning, which isn’t necessary given EventBridge’s native integration with S3 events.