Free Google Professional-Machine-Learning-Engineer Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for Professional Machine Learning Engineer certification exam which are developed and validated by Google subject domain experts certified in Google Professional-Machine-Learning-Engineer . These practice questions are update regularly as we keep an eye on any recent changes in Professional Machine Learning Engineer syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Google Professional-Machine-Learning-Engineer exam questions and pass your exam on first try.
latest advertising campaign. You have streamed 500 MB of campaign data into BigQuery. You want to
query the table, and then manipulate the results of that query with a pandas dataframe in an Al
Platform notebook. What should you do?
I’m thinking A is cleanest since it skips file transfers entirely and directly loads data into pandas. A
Actually, A makes the most sense if your notebook environment already has the needed permissions; it’s the quickest way to get data into pandas without manual file handling. Options B, C, and D add unnecessary overhead.
based on historical transactional data You anticipate changes in the feature distributions and the
correlations between the features in the near future You also expect to receive a large volume of
prediction requests You plan to use Vertex Al Model Monitoring for drift detection and you want to
minimize the cost. What should you do?
I think D makes the most sense here. Using feature attributions gives a deeper insight into drift while lowering the prediction-sampling-rate near 0 means much less data is monitored overall, which should save costs despite the extra overhead of attributions. The key is balancing fewer samples with more detailed monitoring, and D nails that better than just tweaking frequency or sampling rates alone.
D, sampling rate near 0 reduces data volume, saving cost despite extra attribution overhead.
website. You are asked to build a model that will recommend new products to the user based on
their purchase behavior and similarity with other users. What should you do?
C imo. Collaborative filtering is the classic choice for recommendations based on user similarity and purchase behavior, even if ratings aren’t explicit. It naturally captures patterns in user interactions.
C/D? Collaborative filtering fits the user similarity part, but if we just have purchase amounts or frequencies, regression might help predict preferences too. Depends on what data is really available.
in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage.
The data collected must not leave the region in which the call originated, and no Personally
Identifiable Information (Pll) can be stored or analyzed. The data science team has a third-party tool
for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select
components for data processing and for analytics. How should the data pipeline be designed?
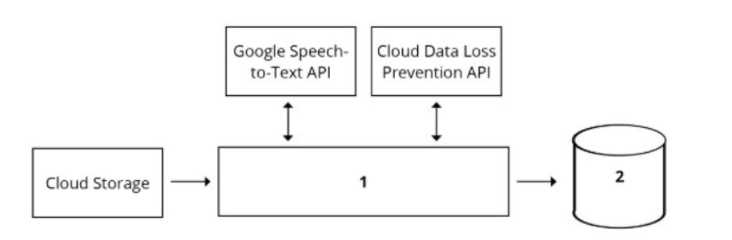
Good point on Cloud SQL handling regional data and ANSI-2011 compliance. I’d say C fits best since Pub/Sub or Datastore won’t provide the SQL interface needed, and Cloud Functions might struggle with scaling to that volume. C it is.
Maybe C since Dataflow can scrub PII well and Cloud SQL keeps data regional.
should you adjust your model to ensure that it converges?
A/D? Increasing batch size (A) can reduce gradient noise, which smooths out loss oscillations, while decreasing learning rate (D) helps prevent overshooting. Both can help, but larger batches give steadier gradients.
If the loss is bouncing around, it usually points to the learning rate being too high rather than batch size issues. Lowering the learning rate (D) lets the model take smaller, more controlled steps, which helps it settle down. Increasing batch size (A) can reduce noise but might not fix oscillations caused by a too-large step. So maybe focusing on tuning the learning rate makes more sense here? Could the oscillations also be from extremely noisy gradients or just a poorly scaled learning rate?
conduct data transformations at scale, but your pipelines are taking over 12 hours to run. To speed
up development and pipeline run time, you want to use a serverless tool and SQL syntax. You have
already moved your raw data into Cloud Storage. How should you build the pipeline on Google Cloud
while meeting the speed and processing requirements?
A/D? Data Fusion’s GUI could speed up development with less coding, but might not handle very large scale as efficiently as BigQuery. Since the data’s in Cloud Storage already, loading into BigQuery (D) seems cleaner for serverless SQL.
Option D, since BigQuery handles massive data natively and removes cluster management hassles.
preliminary experiments running on your on-premises CPU-only infrastructure were encouraging,
but have slow convergence. You have been asked to speed up model training to reduce time-to-
market. You want to experiment with virtual machines (VMs) on Google Cloud to leverage more
powerful hardware. Your code does not include any manual device placement and has not been
wrapped in Estimator model-level abstraction. Which environment should you train your model on?
Maybe B could work if you want a big speed boost, but since the code isn’t set up for multi-GPU, it might not use all 8 efficiently. D’s just beefier CPU, so probably slower than GPU options.
It’s C since pre-installed GPU support beats manual setup and unoptimized multi-GPU use.
After receiving the dataset, you discover that less than 1% of the readings are positive examples
representing failure incidents. You have tried to train several classification models, but none of them
converge. How should you resolve the class imbalance problem?
D imo, completely balancing the classes by removing negatives can make the training much simpler and faster, especially when positives are so rare. Sure, you lose some data, but it avoids the complexity of carefully tuning weights or generating synthetic samples. Sometimes straightforward equal sampling helps models converge better by not overwhelming them with negatives. Plus, with less data, training might be quicker, letting you experiment more. The key is to keep enough negatives while making the dataset manageable and balanced for the model to learn meaningful patterns.
C. Downsampling negatives and upweighting positives strikes a good balance without losing too much info, unlike D that drops too many negatives or A which could add noisy synthetic data. Makes the model focus on real failure signals.
are accurate descriptions for each table in BigQuery, and you are searching for the proper BigQuery
table to use for a model you are building on AI Platform. How should you find the data that you
need?
Maybe D, since INFORMATION_SCHEMA is always available without extra setup needed.
Maybe D could work here too, since INFORMATION_SCHEMA tables give you metadata about all your BigQuery tables. You can run queries to list table names and details across datasets without needing extra tools or setup. It’s more manual than Data Catalog but might be useful if you want a quick snapshot or don’t have Data Catalog fully set up yet.
Also, it doesn’t rely on external indexing or tagging, just the metadata that’s already there, so it can be pretty straightforward for finding tables by name or basic info. It’s not as user-friendly for searching descriptions, but definitely an option
containers, and a service that supports autoscaling and monitoring for online prediction requests.
Which platform components should you choose for this system?
The question highlights autoscaling and monitoring for online predictions, so B fits best.
B/D? B nails scheduled retraining and deployment with autoscaling, but D covers custom containers for training too. If Docker’s needed just for deployment, B fits better; otherwise, D could be the safer bet.
million X-ray images, each roughly 2 GB in size. You are using Vertex AI Training to run a custom
training application on a Compute Engine instance with 32-cores, 128 GB of RAM, and 1 NVIDIA P100
GPU. You notice that model training is taking a very long time. You want to decrease training time
without sacrificing model performance. What should you do?
D imo, distributing the training across multiple GPUs or nodes should cut time significantly without risking compatibility issues like with TPUs. Plus, more memory alone (A) won’t speed up GPU-bound tasks much.
B/D? I’m thinking D makes more sense here since the setup only has one GPU, so scaling out with tf.distribute.Strategy would speed things up. Also, the question doesn’t confirm TPU support or that the code can run on TPU, so swapping to a v3-32 TPU might cause compatibility issues or need code changes. Increasing memory alone (A) won’t help much without more GPUs or better parallelism. Early stopping (C) might reduce training time but risks hurting model performance, which the question says we don’t want. So D should be the best bet if distributed training is implemented.
based on their purchase history. You want to explore model performance using multiple model
architectures, store training data, and be able to compare the evaluation metrics in the same
dashboard. What should you do?
B. Cloud Composer can automate the whole training pipeline, including multiple runs, but it doesn’t inherently provide a dashboard for comparing metrics. You’d still need to integrate with another tool for visualization. That makes it less straightforward for the question’s goal of having one place to compare models.
C is tempting since AI Platform supports multiple jobs, but managing and comparing many jobs manually can get messy without a proper experiment tracking setup, which Kubeflow offers natively.
It’s A because AutoML Tables lets you easily try different models and provides a dashboard to compare metrics all in one place, which fits the need for exploring multiple architectures and tracking results.
sources and sends them to users. You need to build a recommendation model that will suggest
articles to readers that are similar to the articles they are currently reading. Which approach should
you use?
B. Since the goal is to find articles similar to the one currently being read, using vector embeddings and similarity makes the most sense. Collaborative filtering (A) depends on user history, which might not help when a user reads new topics. Logistic regression for each user (C) seems impractical given the variety of users and articles. Manually labeling articles (D) is too time-consuming and focuses on categories, not similarity, so B still fits best here.
It’s B, since vector similarity directly measures article closeness without needing user data.
different training strategies. First, you trained the model using a single GPU, but the training process
was too slow. Next, you distributed the training across 4 GPUs using tf.distribute.MirroredStrategy
(with no other changes), but you did not observe a decrease in training time. What should you do?
D imo, increasing batch size usually helps utilize multiple GPUs better.
I’m thinking option A might be worth reconsidering. If the dataset isn’t properly sharded across the GPUs, each GPU could be doing the same work, so no speedup happens. Distributing the dataset explicitly makes sure each GPU processes a different slice. Just switching to MirroredStrategy alone doesn’t automatically handle how data is fed. Could that explain why training time stayed the same? What if they did increase batch size but didn’t shard the data? Would that still cause no improvement?
for many years, and you have deployed models that predict customers’ vacation patterns. You have
observed that customers’ vacation destinations vary based on seasonality and holidays; however,
these seasonal variations are similar across years. You want to quickly and easily store and compare
the model versions and performance statistics across years. What should you do?
D imo, Vertex ML Metadata fits the event-based tracking and slicing perfectly.
Probably A since Cloud SQL can store all the stats in one place, making it straightforward to query and compare across years without depending on specific ML tools.