Free Databricks-Generative-AI-Engineer-Associate Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for Generative AI Engineer Associate certification exam which are developed and validated by Databricks subject domain experts certified in Databricks-Generative-AI-Engineer-Associate . These practice questions are update regularly as we keep an eye on any recent changes in Generative AI Engineer Associate syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Databricks-Generative-AI-Engineer-Associate exam questions and pass your exam on first try.
document Q&A for structured HR policies, but the answers returned are frequently incomplete and
unstructured It seems that the retriever is not returning all relevant context The Generative Al
Engineer has experimented with different embedding and response generating LLMs but that did not
improve results.
Which TWO options could be used to improve the response quality?
Choose 2 answers
A imo, headers clarify context; B helps avoid missing info with bigger chunks.
Maybe A and D. Adding section headers helps the retriever find relevant parts easier, and a larger embedding model could capture more detailed context that smaller ones miss. B might risk too big chunks confusing the retriever.

Assuming they intend to use Databricks managed embeddings with the default embedding model,
what should be the next logical function call?
B/C? You’d usually need to create or sync the index before querying it with similarity_search (D). Between B and C, create_delta_sync_index (B) sounds like it handles updating or syncing, which might be necessary if the index already exists and data is changing. create_direct_access_index (C) might be for initial setup. If this is the very first setup, then C could make sense; if updating or syncing, then B. So it really depends on whether the code snippet indicates an existing index or not.
D, since testing retrieval with similarity_search() comes after the index setup.
is getting an error.

Assuming the API key was properly defined, what change does the Generative AI Engineer need to
make to fix their chain?
A)

B)

C)

D)

Probably B makes the most sense here. The key issue seems to be that the prompt isn’t being passed as an argument when initializing the LLMChain, which is essential. Options A and D either don’t show the prompt explicitly passed or add extra steps that aren’t needed. Option C might be close, but B clearly shows the fix by including prompt=prompt in the chain constructor, so that should resolve the error.
C imo, since it explicitly adds the prompt argument when creating the LLMChain, fixing the error.
large language model (LLM). They need a foundation LLM with a large context window.
Which model fits this need?
DistilBERT and DBRX can be dropped since their context windows are pretty limited. Between B and C, MPT-30B is designed with extended context lengths in mind, often going beyond Llama2's standard windows. Even though Llama2-70B has some extended context versions, MPT-30B’s architecture prioritizes longer contexts out of the box, making B the more straightforward pick for a large context window need.
Makes sense to rule out DistilBERT and DBRX since they’re not known for large context windows. I agree with B since MPT-30B is built specifically to handle longer contexts than typical Llama models. B
outputs.
Which action would be most effective in mitigating the problem of offensive text outputs?
Maybe D makes the most sense since offensive outputs usually come from bad input data. Stopping the problem before it starts seems better than just warning users or limiting access.
D, because cleaning the data before use directly targets the offensive content source.
following business objective: answer employee HR questions using HR PDF documentation.
Which set of high level tasks should the Generative AI Engineer's system perform?
I’m ruling out B because summarizing all HR docs first seems risky—important details might get lost or generalized. Between A and D, D’s approach of chunking docs makes more sense for handling large PDFs, since it avoids overloading the LLM’s context window. A’s method of averaging embeddings per doc could miss out on specific details buried in different sections, which are often needed in HR questions. Does anyone think A’s simpler embedding comparison could actually perform better in scenarios with simpler, more straightforward queries?
C imo, option D is solid but C adds a historical layer by factoring in previous questions, which could improve relevance and personalization for employee queries. This might be especially useful if the HR questions tend to repeat or have common patterns. Also, leveraging ALS for embeddings could capture subtle relationships that chunk-based methods might miss. It feels like a more data-driven approach overall, though it might be more complex to set up compared to D’s straightforward chunking and retrieval. Still, I wouldn’t rule out C if the goal includes learning from past interaction trends
team. The system can answer text based questions about the monster truck team, lookup event
dates via an API call, or query tables on the team’s latest standings.
How could the Generative AI Engineer best design these capabilities into their system?
D misses the point since embedding all data in the prompt isn’t scalable or updatable easily.
B/C? I get why B is popular since it lets the agent pick the right tool on the fly, which fits well for mixed query types. But C’s approach of telling the LLM exactly how to categorize queries is simpler to implement without building a full agent system. It might be more lightweight and easier to debug, especially if you want strict control over how queries get routed. Still, B feels more flexible in the long run with multiple APIs and data sources.
require parsing and extracting the following information: order ID, date, and sender email. Here’s a
sample email:
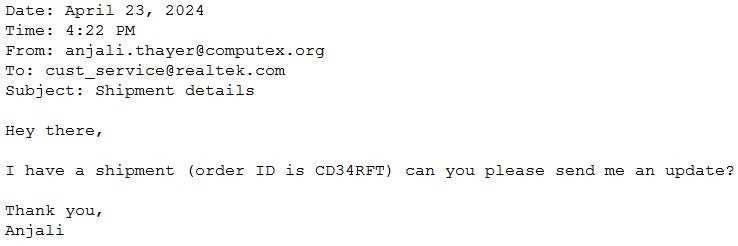
They will need to write a prompt that will extract the relevant information in JSON format with the
highest level of output accuracy.
Which prompt will do that?
It’s B, the example JSON really helps the model understand the output structure clearly, which should boost accuracy compared to just saying "return in JSON."
This is not C, since human-readable doesn't guarantee JSON output.
A Generative Al Engineer is tasked with developing a RAG application that will help a small internal group of experts at their company answer specific questions, augmented by an internal knowledge base. They want the best possible quality in the answers, and neither latency nor throughput is a
huge concern given that the user group is small and they’re willing to wait for the best answer. The topics are sensitive in nature and the data is highly confidential and so, due to regulatory requirements, none of the information is allowed to be transmitted to third parties. Which model meets all the Generative Al Engineer’s needs in this situation?
A, because it’s lightweight enough for secure on-prem use without third-party data sharing.
A imo, Dolly 1.5B is smaller and easier to run fully on-prem without sending data out, which matches the confidentiality need. The question doesn’t guarantee they have big hardware for Llama2-70B.
personalized birthday poems based on their names.
Which technique would be most effective in safeguarding the application, given the potential for
malicious user inputs?
A imo, since just limiting time (B) or boosting compute (D) doesn't stop bad inputs. Also, letting the convo continue with a warning (C) still risks harmful content slipping through.
It’s A for sure. B and D don’t actually prevent anything harmful; they just try to limit interaction or speed. C lets the bad input slide by, which could lead to inappropriate outputs. Having a solid filter that blocks harmful inputs outright is the best way to keep the app safe and maintain control over the content generated.
document sections. They would like to store the chunks in a Vector Search index. The current format
of the dataframe has two columns: (i) original document file name (ii) an array of text chunks for
each document.
What is the most performant way to store this dataframe?
B. Storing one chunk per row makes the most sense since vector search works best when each vector corresponds to a single row. Having unique IDs per chunk also helps with traceability and retrieval speed. Options A and C keep chunks grouped by document, which could slow down searches because you’d have to extract or flatten later anyway. Option D adds unnecessary complexity with JSON files, which isn’t as fast or scalable for typical vector DB queries. So B is definitely the more efficient and practical approach here.
It’s B. Storing one chunk per row with unique IDs lets you index and search vectors directly without unpacking arrays, which is faster and scales better than grouped or JSON storage.
questions about specific showtimes for movies currently playing at their local theater. They already
have the location of the user provided by location services to their agent, and a Delta table which is
continually updated with the latest showtime information by location. They want to implement this
new capability In their RAG application.
Which option will do this with the least effort and in the most performant way?
C imo, embedding the Delta table content into a vector index seems like overkill for this use case. Showtimes are structured data, so turning them into text and embeddings just adds unnecessary complexity and potential latency. Also, vector search might not guarantee up-to-date info if the embeddings aren’t refreshed frequently.
D could add extra overhead maintaining another database, which seems unnecessary given the Delta table is already being updated continuously. Direct access or a feature store seems more straightforward if performance holds up.
B/D? B feels most direct and avoids extra syncing or embedding delays.
news articles and stock prices.
The design requires the use of stock prices which are stored in Delta tables and finding the latest
relevant news articles by searching the internet.
How should the Generative AI Engineer architect their LLM system?
D. This lets the LLM directly access both the Delta tables and live web data, which fits the need for up-to-date info better than pre-stored vectors or summaries.
It’s C because storing both stocks and news in a vector store allows fast retrieval with up-to-date info, and RAG handles combining external data nicely without needing live tool calls.
queries. The chatbot is built on a large language model (LLM) and is conversational. However, to
maintain the chatbot’s focus and to comply with company policy, it must not provide responses to
questions about politics. Instead, when presented with political inquiries, the chatbot should
respond with a standard message:
“Sorry, I cannot answer that. I am a chatbot that can only answer questions around insurance.”
Which framework type should be implemented to solve this?
C/D? Could be contextual since it’s about topic restriction, but compliance fits too.
This feels less about broad safety or general context and more about enforcing a specific company rule, so D makes the most sense. The chatbot isn’t just avoiding unsafe topics; it’s following a clear policy restriction on political content. That’s the core of compliance guardrails—making sure the AI stays within defined organizational guidelines rather than just handling safety or context. So I’d rule out A and C here because those are more about general content safety or relevance, not strict policy adherence.
topic within 10 days of the date specified An example query might be "Tell me about monster truck
news around January 5th 1992". They want to do this with the least amount of effort.
How can they set up their Vector Search index to support this use case?
I think option A might also make sense here, since splitting articles into 10-day blocks could simplify the search by limiting the scope without complex metadata filters. It avoids any potential limitations on range filtering within Databricks vector search itself. But on the downside, it might be less flexible if someone wants a different date range or overlapping periods. Anyone confirmed if Databricks supports dynamic date range filters inside vector search queries? That detail could really tip the scale between A and B.
I agree with B since metadata filtering handles the date range well, unlike pure vector search. B