Free Cisco 400-007 Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for 400-007 certification exam which are developed and validated by Cisco subject domain experts certified in Cisco 400-007 . These practice questions are update regularly as we keep an eye on any recent changes in 400-007 syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Cisco 400-007 exam questions and pass your exam on first try.
loop would be reduced by using this design?
B - OSPF LFA is designed to minimize short-lived micro loops during topology changes.
B/D? LFA mainly reduces micro loops, but REP deals with ring topologies too. Since the question specifies OSPF LFA, micro loops (B) still seem more relevant than REP loops (D).
chosen VXLAN as encapsulation technology The customer is concerned about miss-configuration of
Layer 2 devices and DC wide outages caused by Layer 2 loops What do you answer?
I’m thinking B could help too since storm control limits broadcast storms, which can happen in a loop scenario. It’s more of a safety net than a prevention tool though. Could it be enough on its own?
C/D? I’m not sure VXLAN itself prevents loops inherently, so A feels off. B seems more like general protection, not a solid loop prevention method. C could work if VPC+ is configured properly to keep loops from access ports, but that depends on having the right hardware and setup. D looks solid if STP is off on the underlay since BPDU Guard would block unexpected BPDUs from causing loops at VTEPs. If the environment disables STP on the underlay, D feels like the safest bet here.
want to use FCoE over this DCI to support synchronous replication. Which two technologies allow for
FCoE via lossless Ethernet or data center bridging? (Choose two.)
Makes sense to rule out A and C since they’re more about physical or traditional transport, not Ethernet losslessness. I’d say D is less likely because while it bundles links, it doesn’t inherently provide Data Center Bridging features needed for FCoE. So sticking with B and E feels right because both extend Ethernet and can support lossless behavior, which is critical for FCoE in a DCI setup.
I’m going with B and E too, but from a different angle. The key is maintaining lossless Ethernet, and both EoMPLS (B) and VPLS (E) can extend Ethernet while supporting Data Center Bridging features required for FCoE. DWDM doesn’t handle Ethernet losslessness since it’s just the optical transport layer, and Multichassis EtherChannel (D) mainly aggregates links but doesn’t guarantee lossless across the DCI. SONET/SDH (C) isn’t Ethernet-based, so less relevant here. So B and E make the most sense for lossless Ethernet over the DCI.
• The CEs cannot run a routing protocol with the PE
• Provide the ability for equal or unequal ingress load balancing in dual-homed CE scenarios.
• Provide support for IPv6 customer routes
• Scale up to 250.000 CE devices per customer.
• Provide low operational management to scale customer growth.
• Utilize low-end (inexpensive) routing platforms for CE functionality.
Which tunneling technology do you recommend?
D imo, LISP handles massive scale and IPv6 without needing CE-PE routing.
B, since GRE is simple and fits low-end CE with no routing to PE.
(Choose three.)
I’m going with B, C, and D as well. Cisco Open Virtual Switch (B) is needed for the virtual networking layer, Nexus switches (C) handle the physical network infrastructure, and UCS (D) provides the compute platform. A and E seem more related to service management and containers, which aren’t core NFVi components here. F is a virtual network function itself, not the infrastructure. So, B, C, and D fit best as the main products used with Red Hat for NFVi.
B/C/D? The Open Virtual Switch is essential for the virtual networking layer, Nexus switches cover the physical network infrastructure, and UCS handles compute resources. These three align well with what’s needed for NFVi alongside Red Hat. A and E seem more related to service management or container platforms, which don’t fit directly into the NFVi stack. F sounds like a function rather than infrastructure, so it’s less likely here.
• A pool of servers is accessed by numerous data centers and remote sites
• The servers are accessed via a cluster of firewalls
• The firewalls are configured properly and are not dropping traffic
• The firewalls occasionally cause asymmetric routing of traffic within the server data center.
Which technology should you recommend to enhance security by limiting traffic that could originate
from a hacker compromising a workstation and redirecting flows at the servers?
It’s C since ACLs directly control allowed sources despite routing twists.
Maybe C is better because limiting source traffic with ACLs on the server side directly blocks unwanted flows regardless of routing issues. uRPF might still drop legit traffic due to asymmetry.
ASN Which multicast address range should be used?
Yeah, B fits best since GLOP's about 233.x.x.x for ASN uniqueness. B
Option B makes the most sense since GLOP addressing is specifically designed to map 16-bit ASNs into the 233.0.0.0/16 multicast block, ensuring uniqueness. The other options fall outside this designated range and don’t align with how GLOP IPs are structured. Even if 32-bit ASN support isn’t clear, B is the only choice that matches the official GLOP allocation criteria.
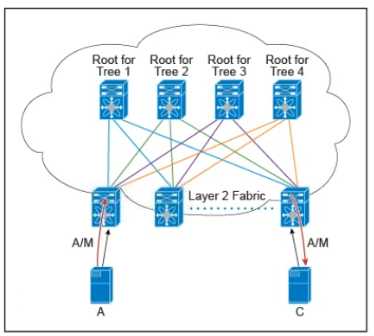
There are multiple trees in the Cisco FabricPath All switches in the Layer 2 fabric share the same view
of each tree. Which two concepts describe how the multicast traffic is load-balanced across this
topology? (Choose two )
It’s definitely not B since all trees won’t be equally used at all times—traffic depends on group membership and sources. Also, C seems off because leaf nodes don’t assign (S.G) to the same tree everywhere; the fabric does hashing to spread groups across different trees. So, A is good because each (S.G) sticks to one tree to maintain order, and E fits since overall multicast traffic balances over all trees for efficiency.
I’m with A and E here. Each (S.G) group sticks to one tree for packet order, so no load-balancing on that level, but overall multicast traffic still spreads across all trees.
Standard? (Choose two.)
E imo, having a solid risk management policy (E) covers ongoing compliance and sets the framework for specific actions like risk analyses. B is kind of a given for any security standard, so that feels like a must-do too.
E imo—establishing risk management policies feels more foundational than just doing one-off risk analyses (A). You need a formal policy in place to guide those analyses and actions. Plus, B makes sense because firewalls are explicitly required to protect cardholder data environments. Antivirus (C) is recommended but not always mandatory, and monitoring policies (D) could overlap with risk management, but policies need a solid framework first. So, E and B for me.
An enterprise wants to migrate an on-premises network to a cloud network, and the design team is
finalizing the overall migration process. Drag and drop the options from the left into the correct order
on the right.
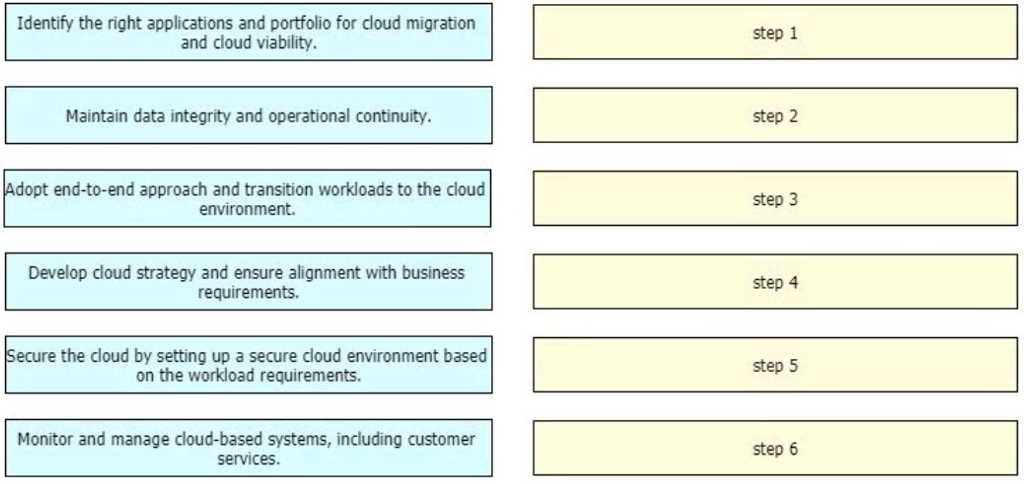
I’d switch the VPN setup and testing steps. Setting up VPN tunnels first, then testing them before you do any routing, helps catch connection issues early and saves headaches down the line.
Starting with assessing the current network is key to understand what you're working with. Then sorting IP conflicts before setting up VPN makes sure you won’t hit issues later on. Testing VPN before routing feels right to confirm link stability.
consider serialization delay? (Choose two )
E (only packet size and line rate affect serialization delay, so B/D are off)
E, C. E makes sense since serialization delay depends on both packet size and link speed, which lines up with what I know. C says serialization delay is the time to transmit the packet on the media, which seems accurate if you think of serialization as the actual bit-by-bit transmission time. Even if it’s a bit ambiguous, propagation delay is a separate concept from serialization delay, so I’m okay with including C here. A and B don’t quite work because serialization delay isn’t fixed—it varies with packet size, so those options feel off.
collected or processed and must remain within its borders?
It’s definitely A. Data sovereignty is the only option that deals directly with a country’s legal claim over data collected or processed within its borders. The others are more technical terms—like replication is just about copying data, not about legal restrictions on location. So for the part about data needing to stay inside the country because of laws, data sovereignty fits perfectly.
A/D? Data sovereignty definitely covers legal control by the country, while replication is more about where copies are stored. Since the question stresses legal rules and borders, A seems more precise.
try to reduce the reconvergence time, but the network is still experiencing delays when having to
reconverge. Which technology will improve the design?
C. Switching to BGP just to fix OSPF reconvergence sounds like overkill. BGP is slower to converge by default and designed for different use cases. Since BFD is already in place but reconvergence is still slow, it might be about how OSPF timers are set or how fast hellos are implemented rather than changing protocols. So, probably better to stick with OSPF optimizations rather than switching protocols here.
I’m thinking A here. OSPF fast hellos can trigger faster failure detection compared to just changing hello and dead timers, which might still be too slow if set high. Since BFD is already in place but reconvergence is still slow, speeding up OSPF’s own hello packets could help. D might help but if intervals are already optimized, it won’t fix the root cause. So, A seems like the better option to improve reconvergence time noticeably.
concerns about unavailability of network resources? (Choose two.)
D imo, network resiliency is about more than just links—it’s the whole design making sure traffic keeps flowing even if something fails. A also fits because you need devices that can handle failures or have backup power. B and C feel more like characteristics than direct factors for availability, and E is too broad since bigger networks don’t automatically mean better uptime.
Option A and D make the most sense since device and network resiliency directly address redundancy and failover, which are key for high availability. Device type or size don’t guarantee uptime by themselves.
plan to prevent infected devices on your network from sourcing random DDoS attacks using forged
source address?
C imo. Strict mode forces the router to verify that the source IP is reachable via the interface it came in on, which really cuts down on spoofed addresses. Loose mode (B) lets packets through as long as the source IP exists somewhere in the routing table, so it’s less strict against spoofing. Since the question is about stopping forged source addresses in DDoS attacks, strict mode fits better if your network routing allows it without dropping legit traffic. A and D don’t directly address source IP validation, so they’re less relevant here.
Actually, D doesn’t make sense since filtering by destination won’t stop spoofed source addresses causing DDoS. A is too broad and not specific to source spoofing prevention. Between B and C, strict mode (C) enforces that packets must come from the expected interface based on routing, which is the best way to block spoofed sources if your network routes are stable. Loose mode (B) lets some spoofed traffic through if routes are asymmetric, so it’s less reliable. So C is the most solid choice if you want to really prevent source address forgery.