Free Microsoft AI-900 Azure AI Fundamentals Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for AI-900 certification exam which are developed and validated by Microsoft subject domain experts certified in Microsoft AI-900 Azure AI Fundamentals . These practice questions are update regularly as we keep an eye on any recent changes in AI-900 syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Microsoft AI-900 Azure AI Fundamentals exam questions and pass your exam on first try.
HOTSPOT Select the answer that correctly completes the sentence. 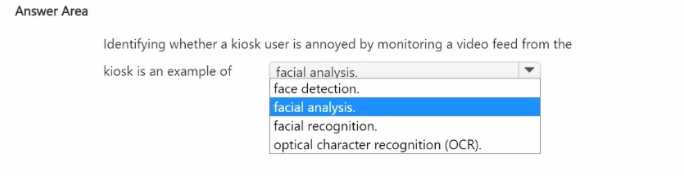
C, since scalability means handling growth, not just cost savings.
C, because it’s about managing bigger workloads, not just reducing expenses.
automatically identify bottles of the correct shape and reject all other items.
Which type of AI workload should the company use?
Isn’t this just classifying images? So C?
DRAG DROP Match the tool to the Azure Machine Learning task. To answer, drag the appropriate tool from the column on the left to its tasks on the right. Each tool may be used once, more than once, or not at all NOTE: Each correct match is worth one point. 
I matched Automated ML with model creation since it automates the process. Designer fits with pipeline building. Notebooks are for custom experiments and coding tasks. This fits their core purposes clearly.
I also went with automated ML for model creation since it’s designed to streamline that. For experimentation, Azure Notebooks makes sense because it’s more hands-on with code. The designer is more about building models visually without coding, so it fits both creation and deployment prep. Some options don’t seem to match anything here, like if there’s a tool focused purely on monitoring or management. I figured the key is focusing on what each tool’s primary strength is rather than trying to fit them all in multiple tasks.
HOTSPOT To complete the sentence, select the appropriate option in the answer area. 
I’m dropping option C here because it doesn’t mention the key update the question focuses on. Only B talks about that specific feature, so it makes the most sense.
Option B sounds right since it highlights the newest feature clearly.
from a chat solution that uses the Azure OpenAI GPT-3.5 model?
C imo, presence penalty directly affects repetition, making responses less predictable.
Option C seems right because presence penalty discourages repeating the same words, which naturally leads to more varied responses. The other options don’t really influence token diversity directly.
HOTSPOT For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. 
B and D are about actual benefits, so they seem right.
I’m seeing B and D as the only realistic yes answers since they talk about AI improving efficiency and insights. A and C feel more about fears than actual benefits or truths.
DRAG DROP Match the Microsoft guiding principles for responsible AI to the appropriate descriptions. To answer, drag the appropriate principle from the column on the left to its description on the right. Each principle may be used once, more than once, or not at all. NOTE: Each correct selection is worth one point. 
I’d match fairness with promoting equality, since it’s about bias and inclusion.
I’d pair privacy with protecting user data since it’s all about confidentiality. Then, reliability and safety seem to go together with making sure the AI system works consistently and avoids harm. For accountability, I agree it’s about audit trails and fixing problems. Transparency should be about explaining how decisions are made clearly. Fairness fits naturally with avoiding any kind of bias or discrimination. Just matching the principle’s main focus helps eliminate confusion quickly.
complete solution.
NOTE: Each correct answer is worth one point.
C imo, since SDKs provide full programmatic access and handle authentication better than CLI. D also works for the same reason, letting JS devs call the service smoothly without dealing with REST details.
Probably A and B. CLI is straightforward for quick commands, and REST API is the base method that everything else builds on, so both definitely count as complete solutions.
B/D? Splitting columns (D) would mix up features and labels, so that’s a no. B makes sense because it keeps the samples intact, which is crucial for training and evaluation.
Probably B, since splitting rows keeps the feature-label pairs intact for both training and evaluation. Splitting columns (D) would separate features and mess up the data.
information m the following documents
• A product troubleshooting guide m a Microsoft Word document
• A frequently asked questions (FAQ) list on a webpage
Which service should you use to process the documents?
Maybe D, since QnA Maker is designed to pull Q&A from different documents and webpages, which fits the need to combine both the Word guide and FAQ list effectively.
It’s D because QnA Maker specializes in extracting Q&A pairs from various sources, making it easier to integrate both the Word guide and the FAQ page into one searchable chatbot.
HOTSPOT For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE; Each correct selection is worth one point. 
I agree with ruling out B and D here. B mentions features that aren’t really part of Azure Machine Learning Studio’s core functionality, and D seems to be describing something more like a cognitive service rather than ML Studio. A and C both directly relate to what ML Studio offers—building and deploying models and managing experiments. So, focusing just on Azure Machine Learning Studio, A and C should be the picks.
B can be ruled out since it talks about capabilities not available in Azure Machine Learning Studio. D also feels off because it's about a different service entirely. So yeah, A and C make the most sense here.
Which two parameters should you use to consume the pipeline? Each correct answer presents part
of the solution.
NOTE: Each correct selection is worth one point.
It’s definitely D and C for me. The REST endpoint is the URL you call to send data for inference, and the authentication key is necessary to access that endpoint securely. The model name doesn’t really matter once the pipeline is published, and the training endpoint is only relevant during training, not for consuming the pipeline.
Guessing C and D make the most sense here since the REST endpoint is where you send requests, and the auth key secures access. The model name and training endpoint seem unrelated to calling the published pipeline.
into predefined brain haemorrhage types.
You need to use machine learning to support early detection of the different brain haemorrhage
types in the images before the images are reviewed by a person.
This is an example of which type of machine learning?
It’s C because the categories are known, so it’s definitely supervised classification.
A/B? I ruled out regression (B) since this isn’t about predicting a number or continuous value. Clustering (A) is unsupervised, but here we have predefined categories, so that doesn’t fit either.
Maybe D is easy to rule out since Whisper is for speech-to-text, not images. GPT-3 and GPT-4 are mainly language models, so they don’t fit image generation either. That leaves B, DALL-E, which is designed for creating images from prompts, so it makes the most sense here.
B imo, since GPT-4 and GPT-3 are mainly for text tasks, and Whisper is for audio transcription. DALL-E is specifically designed for creating images from text.
HOTSPOT You have the following apps: • App1: Uses a set of images and photos to extract brand names • App2: Enables touchless access control for buildings Which Azure Al Vision service does each app use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 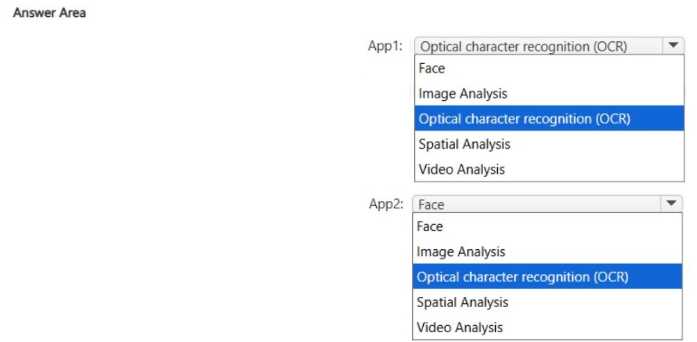
For App1, I think it’s less about just reading text and more about identifying specific brands, so Custom Vision makes sense since it’s trained for custom image classification. The Read API would be more general OCR, but here the goal is brand recognition. As for App2, touchless access control likely involves identifying people or verifying identities, so Face API fits better than just general object detection. So I’d pair App1 with Custom Vision and App2 with Face API based on their core functions.
App1 is probably using the Read API because it's extracting text (brand names) specifically from images. Even though Custom Vision handles image classification, extracting text is more about OCR capabilities, which the Read API does. For App2, touchless access suggests facial recognition or identity verification, so Face API fits better than Video Analyzer since it focuses on people recognition rather than video content analysis. So I’d pick Read API for App1 and Face API for App2.