Home/databricks/Free Databricks-Certified-Associate-Developer-for-Apache-Spark-3.0 Actual Exam Questions
Free Databricks-Certified-Associate-Developer-for-Apache-Spark-3.0 Actual Exam Questions
The questions for this exam were last updated on January 7, 2026
Dumps Box (DumpsBox) offers up-to-date practice exam questions for Certified Associate Developer certification exam which are developed and validated by Databricks subject domain experts certified in Databricks-Certified-Associate-Developer-for-Apache-Spark-3.0 . These practice questions are update regularly as we keep an eye on any recent changes in Certified Associate Developer syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Databricks-Certified-Associate-Developer-for-Apache-Spark-3.0 exam questions and pass your exam on first try.
The code block displayed below contains an error. The code block is intended to perform an outer join of DataFrames transactionsDf and itemsDf on columns productId and itemId, respectively. Find the error. Code block: transactionsDf.join(itemsDf, [itemsDf.itemId, transactionsDf.productId], "outer")
Select one option, then reveal solution.
Question No. 2
Which of the following code blocks shows the structure of a DataFrame in a tree-like way, containing both column names and types?
Select one option, then reveal solution.
Question No. 3
Which of the following code blocks reads the parquet file stored at filePath into DataFrame itemsDf, using a valid schema for the sample of itemsDf shown below? Sample of itemsDf: 1. +------+-----------------------------+-------------------+ 2. |itemId|attributes |supplier | 3. +------+-----------------------------+-------------------+ 4. |1 |[blue, winter, cozy] |Sports Company Inc.| 5. |2 |[red, summer, fresh, cooling]|YetiX | 6. |3 |[green, summer, travel] |Sports Company Inc.| 7. +------+-----------------------------+-------------------+
Select one option, then reveal solution.
Question No. 4
Which of the following code blocks returns a 2-column DataFrame that shows the distinct values in column productId and the number of rows with that productId in DataFrame transactionsDf?
Select one option, then reveal solution.
Question No. 5
The code block shown below should return an exact copy of DataFrame transactionsDf that does not include rows in which values in column storeId have the value 25. Choose the answer that correctly fills the blanks in the code block to accomplish this.
Select one option, then reveal solution.
Question No. 6
The code block displayed below contains an error. The code block should configure Spark to split data in 20 parts when exchanging data between executors for joins or aggregations. Find the error. Code block: spark.conf.set(spark.sql.shuffle.partitions, 20)
Select one option, then reveal solution.
Question No. 7
The code block displayed below contains an error. The code block is intended to return all columns of DataFrame transactionsDf except for columns predError, productId, and value. Find the error. Excerpt of DataFrame transactionsDf: transactionsDf.select(~col("predError"), ~col("productId"), ~col("value"))
Select one option, then reveal solution.
Question No. 8
Which of the following statements about executors is correct, assuming that one can consider each of the JVMs working as executors as a pool of task execution slots?
Select one option, then reveal solution.
Question No. 9
Which of the following code blocks returns a single-column DataFrame showing the number of words in column supplier of DataFrame itemsDf? Sample of DataFrame itemsDf: 1. +------+-----------------------------+-------------------+ 2. |itemId|attributes |supplier | 3. +------+-----------------------------+-------------------+ 4. |1 |[blue, winter, cozy] |Sports Company Inc.| 5. |2 |[red, summer, fresh, cooling]|YetiX | 6. |3 |[green, summer, travel] |Sports Company Inc.| 7. +------+-----------------------------+-------------------+
Select one option, then reveal solution.
Question No. 10
Which of the following code blocks immediately removes the previously cached DataFrame transactionsDf from memory and disk?
Select one option, then reveal solution.
Question No. 11
Which of the following code blocks returns a DataFrame that matches the multi-column DataFrame itemsDf, except that integer column itemId has been converted into a string column?
Select one option, then reveal solution.
Question No. 12
The code block displayed below contains an error. The code block should create DataFrame itemsAttributesDf which has columns itemId and attribute and lists every attribute from the attributes column in DataFrame itemsDf next to the itemId of the respective row in itemsDf. Find the error. A sample of DataFrame itemsDf is below. Code block: itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")
Select one option, then reveal solution.
Question No. 13
Which of the following code blocks creates a new 6-column DataFrame by appending the rows of the 6-column DataFrame yesterdayTransactionsDf to the rows of the 6-column DataFrame todayTransactionsDf, ignoring that both DataFrames have different column names?
Select one option, then reveal solution.
Question No. 14
The code block shown below should return the number of columns in the CSV file stored at location filePath. From the CSV file, only lines should be read that do not start with a # character. Choose the answer that correctly fills the blanks in the code block to accomplish this. Code block: __1__(__2__.__3__.csv(filePath, __4__).__5__)
Select one option, then reveal solution.
Question No. 15
In which order should the code blocks shown below be run in order to create a DataFrame that shows the mean of column predError of DataFrame transactionsDf per column storeId and productId, where productId should be either 2 or 3 and the returned DataFrame should be sorted in ascending order by column storeId, leaving out any nulls in that column? DataFrame transactionsDf: 1. +-------------+---------+-----+-------+---------+----+ 2. |transactionId|predError|value|storeId|productId| f| 3. +-------------+---------+-----+-------+---------+----+ 4. | 1| 3| 4| 25| 1|null| 5. | 2| 6| 7| 2| 2|null| 6. | 3| 3| null| 25| 3|null| 7. | 4| null| null| 3| 2|null| 8. | 5| null| null| null| 2|null| 9. | 6| 3| 2| 25| 2|null| 10. +-------------+---------+-----+-------+---------+----+ 1. .mean("predError") 2. .groupBy("storeId") 3. .orderBy("storeId") 4. transactionsDf.filter(transactionsDf.storeId.isNotNull()) 5. .pivot("productId", [2, 3])
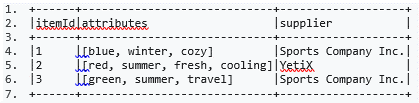 Code block: itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")
Code block: itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")