Free Cisco 350-901 Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for 350-901 certification exam which are developed and validated by Cisco subject domain experts certified in Cisco 350-901 . These practice questions are update regularly as we keep an eye on any recent changes in 350-901 syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Cisco 350-901 exam questions and pass your exam on first try.
DRAG DROP Refer to the exhibit.  Drag and drop the correct parts of the Dockerfile from the left onto the item numbers on the right that match the missing sections in the exhibit to complete the Dockerfile to successfully build and deploy a container running a Python application. Not all parts of the Dockerfile are used.
Drag and drop the correct parts of the Dockerfile from the left onto the item numbers on the right that match the missing sections in the exhibit to complete the Dockerfile to successfully build and deploy a container running a Python application. Not all parts of the Dockerfile are used. 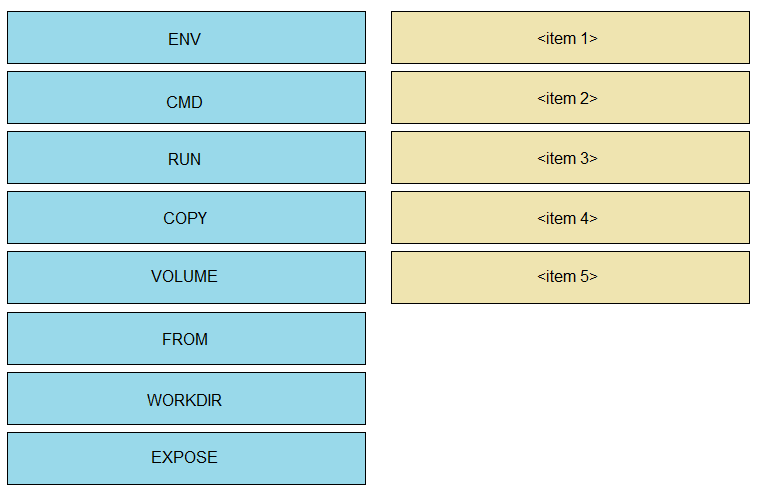
I swapped the order a bit from others here. I put the WORKDIR (D) first to set the folder, then COPY the requirements file (C) right after so pip install (B) can run properly with that file in place. The base image (A) definitely kicks things off, so it’s first. That way, dependencies get installed after copying only the requirements, which avoids reinstalling every time app files change. Seems cleaner and should build faster with caching.
B for installing dependencies after copying requirements, then C to copy app files in place.
on behalf of an end user.
Which two parameters are specified in the HTTP request coming back to the application as the end
user grants access? (Choose two.)
D/E for sure. The code is what the app needs next, and state matches the response to the request, stopping attacks. Access tokens come later after exchanging the code, so A or B don’t fit here.
D imo, the code is definitely returned so the app can get tokens. E makes sense too since the state helps prevent CSRF attacks and ties the response to the original request.
branch called ‘devcor-432436127a-enhance4‘. When merging the branch to production, conflicts
occurred. Which Git command must the developer use to recreate the pre-merge state?
It’s B because git merge --abort cancels the merge and resets everything to how it was before you started merging, so you don’t have to worry about the conflicts messing up your branch.
B tbh, git merge -abort stops the merge and resets to before merging started.
connect the environments to an SDWAN. The SDWAN edge VM is provided as an image in each of the
relevant clouds and can be given an identity and all required configuration via cloud-init without
needing to log into the VM once online.
Which configuration management and/or automation tooling is needed for this solution?
I’m thinking D on this too. Since the VM image comes ready and cloud-init sets everything up on startup, Terraform alone should handle spinning up the VMs in each cloud. No need to add Ansible or NSO if configuration is baked in and automated at launch.
D Cloud-init handles config; Terraform handles provisioning only.
Refer to the exhibit.  An engineer is implementing the response for unrecoverable REST API errors. Which message needs to be placed on the snippet where the code is missing to complete the print statement?
An engineer is implementing the response for unrecoverable REST API errors. Which message needs to be placed on the snippet where the code is missing to complete the print statement?
Guessing B too because the code snippet clearly checks for a 404 status, which means the resource isn’t found. The message about missing data fits perfectly here.
Probably B since the variable name suggests a 404 error, which means data not found.
DRAG DROP Drag and Drop the application requirement on the left onto the database type that should be selected for the requirement on the right. 
Product catalog fits best with A since it needs strong schema and relationships. Session data is a clear match for C because it prioritizes speed over complex queries. Customer profiles seem flexible, so B works well there.
I’d go with A for product catalog since structured queries and relationships matter most there. Session data fits C because it’s all about fast reads/writes, and B suits customer profiles for flexible, semi-structured info.
Refer to the exhibit. 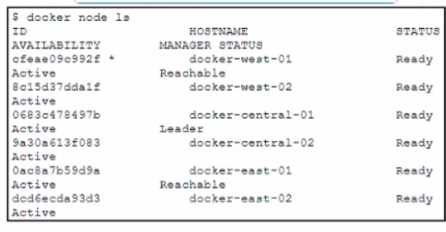 A Docker swarm cluster is configured to load balance services across data centers in three different geographical regions west central and east. The cluster has three manager nodes and three worker nodes Anew service named cisco.devnet is being deployed. The service has these design requirements • All containers must be hosted only on nodes in the central region • The service must run only on nodes that are ineligible for the manager role Which approach fulfills the requirements?
A Docker swarm cluster is configured to load balance services across data centers in three different geographical regions west central and east. The cluster has three manager nodes and three worker nodes Anew service named cisco.devnet is being deployed. The service has these design requirements • All containers must be hosted only on nodes in the central region • The service must run only on nodes that are ineligible for the manager role Which approach fulfills the requirements?
C/D? I’m ruling out A because setting up a new cluster seems overkill and unrelated to filtering nodes by eligibility. B makes no sense since replicas 0 means no containers run. D feels hacky and not standard practice.
D imo, the control flag thing sounds sketchy and not really how Docker swarm handles scheduling. You want something explicit and built-in like placement constraints (C) that can filter nodes by labels, such as region and manager eligibility. B doesn’t make sense because setting replicas to 0 means no containers run at all. A could work but adds unnecessary complexity by creating a new cluster when constraints solve it neatly within the existing one. So C still feels like the cleanest, most Docker-native way to meet both requirements here.
Refer to the exhibit.  An application is created to serve an enterprise Based on use and department requirements, changes are requested quarterly Which application design change improves code maintainability?
An application is created to serve an enterprise Based on use and department requirements, changes are requested quarterly Which application design change improves code maintainability?
Maybe D, verbose names make it easier to understand code changes later.
Does the question specify the programming language or framework used? D
use their username and passwords to login into then profile and complete their order For this reason
the application must store user passwords Which approach ensures that an attacker wifi need to
crack the passwords one at a time?
It’s C because salting makes each password hash unique, so attackers can’t just crack one hash and apply it to multiple accounts. This forces them to crack each password separately.
I get why salting (C) is popular, but what about peppering (A)? Pepper adds a secret value not stored with the hashes, which means even if the attacker gets the database, they still need the pepper to crack the passwords. That could force them to guess passwords one at a time too. Does peppering offer better protection against bulk cracking than salting alone?
DRAG DROP A developer is creating a Python script to analyze errors during REST API call operations. The script will be used with Cisco solution and devices. Drag and drop the code from the bottom to the box where the code is missing to implement control flow for handling unrecoverable REST API calls. Not all options are used. 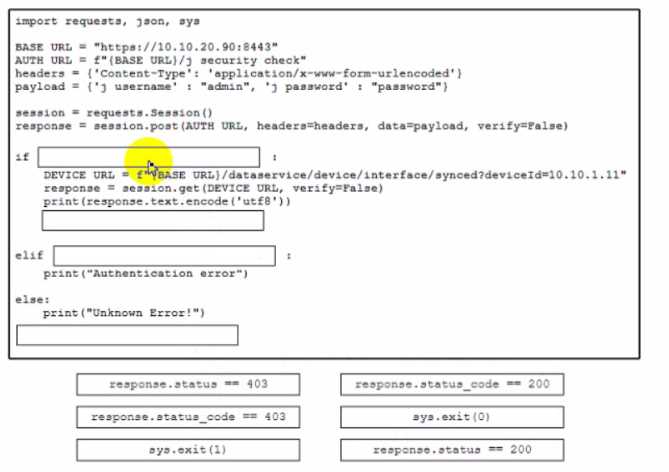
I’m seeing this more as a question about proper error escalation. The goal is to catch unrecoverable API call failures and stop the process cleanly. So, the code that does a try-except block and then raises the exception again or exits seems right. Anything that just logs without halting could cause hidden issues downstream. Also, silently retrying or ignoring errors doesn’t align with handling unrecoverable states effectively.
I think the key is focusing on how the script should behave when it hits an unrecoverable error. The snippet that just retries endlessly or swallows errors won’t fit. So, the code that raises an exception or logs then exits makes more sense. Also, since it’s about REST API calls, handling HTTP status codes like 4xx or 5xx errors explicitly seems right. So the snippet that inspects the response and immediately stops or raises an error aligns best with the idea of controlling flow for unrecoverable conditions.
used in the application for logging?
Not D, C is better since 12-factor apps just stream logs to stdout without extra handling.
It’s C since 12-factor apps aim for simplicity, just streaming logs to stdout without fuss.
Refer to the exhibit. 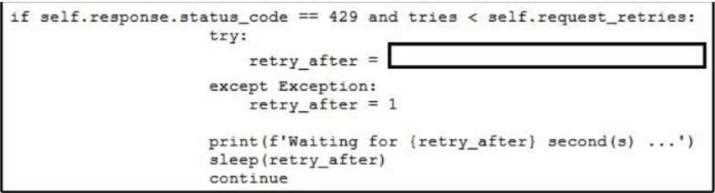 Which line of code needs to be placed on the snippet where the code is missing to provide APl rate- limiting to the requests?
Which line of code needs to be placed on the snippet where the code is missing to provide APl rate- limiting to the requests?
B looks right since headers use get() not post(), and response fits better here.
The snippet seems to use a local variable named response rather than self.response, so C and A can be ruled out because they reference self.response. Also, using .post() on headers doesn’t make sense since headers are typically accessed with .get(). That leaves B as the clean and correct choice because it uses response.headers.get('Retry-After') with proper quotes. D is invalid too because it uses .post(). So yeah, B fits best for standard header retrieval syntax here.
DRAG DROP Drag and drop the code snippets from the bottom onto the boxes where the code is missing to deploy three Cisco UCS servers each from a different template Not all options ate used. 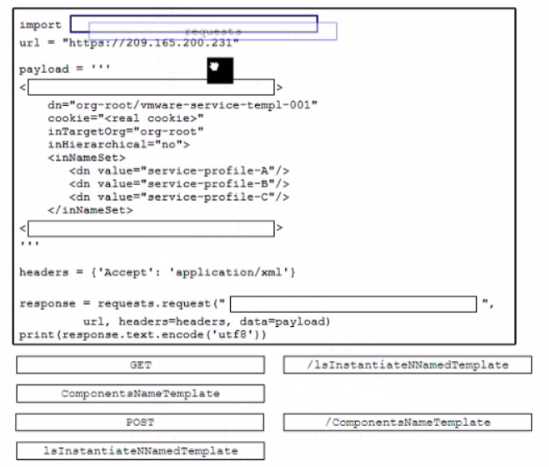
Hey, does anyone know what specific code snippets are available to drag here? The screenshot isn’t clear enough for me to identify them properly.
FILL BLANK Fill in the blanks to complete the Python script to enable the SSID with a name of “371767916” in the network resource “11111111” using the Meraki Dashboard API. 
I’m ruling out A since it uses POST instead of PUT, and we need to update an existing SSID, not create a new one. C and D both look good, but D’s payload seems clearer about enabling the SSID.
I’m going with D on this one because it uses PUT with the proper endpoint format including both network ID and SSID number. Plus, the payload clearly sets the name to “371767916” and enables the SSID, which matches what the question is asking for. The other options either miss the enable flag or don’t use the right HTTP method for updating. This feels like a straightforward API update call, so D’s the best match.
Refer to the exhibit. 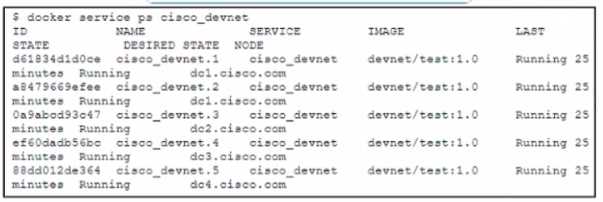 The cisco_devnet Docker swarm service runs across five replicas The development team tags and imports a new image named devnet'test 1 1 and requests that the image be upgraded on each container There must be no service outages during the upgrade process Which two design approaches must be used? (Choose two.)
The cisco_devnet Docker swarm service runs across five replicas The development team tags and imports a new image named devnet'test 1 1 and requests that the image be upgraded on each container There must be no service outages during the upgrade process Which two design approaches must be used? (Choose two.)
A and E make sense to keep all replicas running during the upgrade with no downtime.
A C, rolling upgrades and VIP without session persistence ensure no downtime.