Free Updated Cisco 300-610 Actual Exam Questions
Dumps Box (DumpsBox) offers up-to-date practice exam questions for 300-610 certification exam which are developed and validated by Cisco subject domain experts certified in Updated Cisco 300-610 . These practice questions are update regularly as we keep an eye on any recent changes in 300-610 syllabus, and when there is update our team quickly adjusts the questions. This commitment to providing the best quality exam prep material to certification aspirants is what makes DumpsBox.com the best certification exam prep website. On top of that, our strong, yet strictly moderated, community based feedback keeps the content clean and current. Each question has helpful community discussion that provides it extra perspective and introduces helpful resources for better exam preparation. This also saves students from other outdated practice questions or illicit exam dumps that can have adverse affects on career. Browse through our Updated Cisco 300-610 exam questions and pass your exam on first try.

An engineer is configuring a QoS policy with these requirements
Match-all AF11 traffic and set it to a DSCP value of 14.
The committed rate must be 10 Mbps with a committed burst rate of 1000 ms
Drop any AF11 traffic that violates these settings.
Any traffic other than af11 must have a DSCP value of 0
The given class-map configuration already exists. Which solution must the engineer use to meet the
requirements?
A)

B)

C)

D)

A vs D, only A explicitly sets the committed burst to 1000 ms as required.
Maybe A is better because it clearly marks AF11 traffic with DSCP 14 and sets policing, while also handling other traffic separately to reset DSCP to 0.
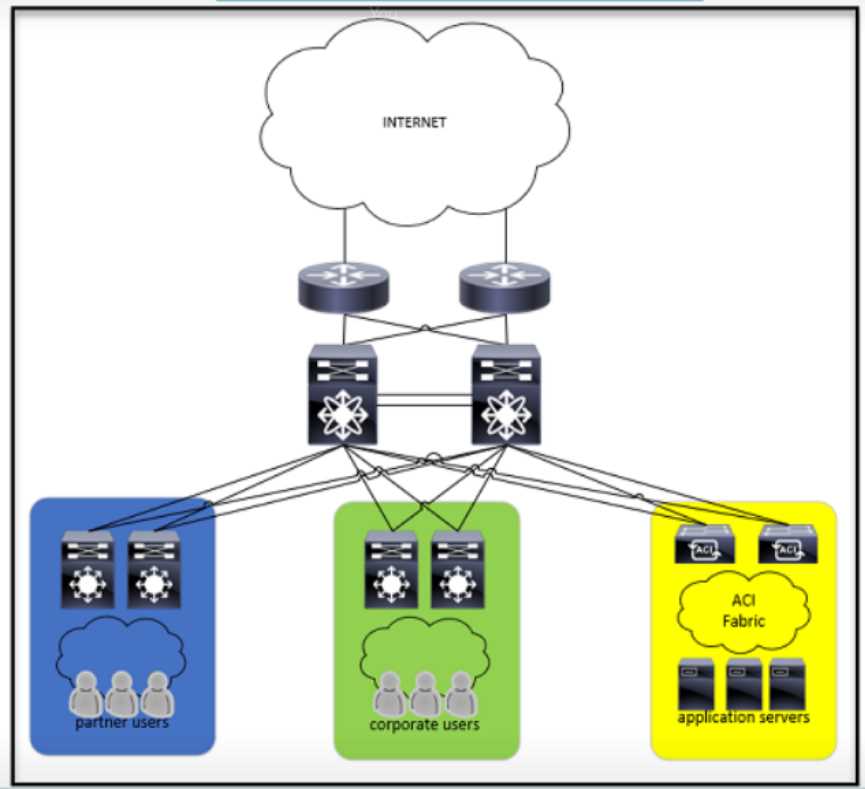
The security team created a new security policy that requires certain types of traffic to be subject to
deep packet inspection The traffic types are
•
internet traffic to application servers
•
internet traffic to corporate users
•
partner network traffic to application servers
•
partner network traffic to corporate users
Where must the next-generation firewalls be inserted to implement the new policy?
Maybe D. Putting the firewall inline between user switches and core cluster lets you handle corporate user traffic efficiently, plus it covers internal flows to app servers better than B, which focuses more on edge traffic.
Thinking about it, I’d go with B here. Placing the firewall inline between the edge router cluster and the core switch cluster should catch all incoming internet and partner traffic to both application servers and corporate users before it spreads inside. That seems to cover all four traffic types in the policy. D might miss some external traffic that goes directly to the core without passing user switches. Also, one-armed setups like A or C wouldn’t fully intercept all flows since they’re not inline. So B makes the most sense for comprehensive deep packet inspection.
Nexus Series Switches The networking team lacks proper programming knowledge and prefers an
automation solution that leverages NXOS commands Any configuration change must use HTTPS for
transport due to a security compliance requirement. Which solution must the architect choose?
Maybe D makes sense too since Terraform can handle HTTPS and automate configurations using existing provider plugins. It’s more infrastructure-focused but can simplify repetitive tasks without deep coding. Still, the team’s lack of programming knowledge might make it tricky compared to something more native like NX-API. Chef is probably too complex here, and Python-API definitely requires coding skills the team doesn’t have. So between A and D, I’d say D could work if they want infrastructure as code, but A fits better for direct NX-OS command use over HTTPS with minimal scripting.
Option B could be ruled out since Python-API likely needs more programming knowledge, which the team lacks. Chef and Terraform (options C and D) are more complex automation tools aimed at infrastructure management but don't directly run NXOS commands over HTTPS as simply as NX-API does. Given the emphasis on using NXOS commands and HTTPS, NX-API (A) still looks like the straightforward choice. It matches the security requirement and is designed specifically for Nexus switches, making it the most practical for a less code-savvy team.
Interconnect toward two upstream Layer 2 switches. The Ethernet interconnection must use all
redundant links and have no impact on the STP domain size.
Which connectivity solution must be used?
C/D? If end host mode really hides the FI from STP, then dual uplinks in D wouldn’t affect STP domain size and still use all links. Otherwise, single uplink in C might be safer to avoid STP impact.
Maybe B. Using switch mode with just one uplink per switch seems like it avoids stretching the STP domain, even if it sacrifices some link redundancy. That fits the requirement about no STP impact.
9000 and Nexus 3000 platforms For the NX-SDK application to run the engineer enables the NX-SDK
feature on the device Then the NX-SDK is imported into the application via an import nx_sdk_py
statement. The engineer creates custom CLI commands and defines custom CLI command syntax
within the sdkThread function When CLI commands originate from an NX-SDK application what class
is this?
C imo, it’s the only one that fits handling CLI commands in NX-SDK apps directly.
It’s C because pyCmdhandler is specifically designed to process CLI commands initiated by the NX-SDK app. A and B are more about output and callbacks, and D isn’t really a handler class.
Refer to the exhibit. An engineer is creating a new data center design for a customer. The design
must support virtual applications, enhance network resilience, and meet these requirements:
• Extend Layer 2 across all network segments to support endpoint mobility.
• Access switches will support up to 20 GB capacity for north-south and east-west traffic.
• Provide fast convergence during link failures.
• MAC address advertisement will not depend on the control plane.
Which solution must the engineer include in the design between the access and distribution
switches?
vPC usually depends on control plane for MAC sync, so it might not meet the MAC advertisement rule here. That makes A less likely; D seems closer but BGP-EVPN in B better fits all requirements. B
Maybe D could work because DVSTB (Distributed Virtual STP) helps with fast convergence and Layer 2 extension without heavy control plane dependency, which seems to match the requirements well.
50 virtualization hosts that require fabric failover connectivity on fabric interconnect B. The
interfaces are bound to a separate pin group to segregate traffic with a CoS value of 0 Which Cisco
UCS Manager feature meets these requirements?
Guessing D because vHBA templates handle fabric failover and CoS settings directly for storage traffic, which fits the requirement better than a general storage policy.
Probably B here. Storage policy sounds like it matches managing storage appliance connections and segregating traffic, especially with CoS 0. The others seem less focused on overall storage setup.
Nexus 7700 Series Switch that is configured with dual supervisors. The feature must meet these
requirements:
• Network resilience must be ensured.
• Network instability for Layer 3 external routing protocols must be reduced.
• Neighbors must be notified when the control plane is restarting.
• Traffic must still be forwarded to peers while neighbor relationships arc restarting.
What should be used to meet these requirements?
B/C? NSF definitely keeps traffic flowing during supervisor failovers, meeting the requirement for uninterrupted forwarding. NSR goes a step further by preserving Layer 3 session states and notifying neighbors about control plane restarts, which helps reduce routing protocol instability. Since the question emphasizes both notifying neighbors and maintaining forwarding, combining these two features seems like the most comprehensive approach. D (BFD) is more about fast failure detection, and A (graceful restart) alone doesn't handle forwarding during supervisor restarts. So, NSF and NSR together
A/B? NSF definitely handles forwarding during failovers, but graceful restart is needed to notify neighbors about control plane restarts. Together they cover all points, so maybe the question expects both concepts combined.
location Top management is concerned about the risk of a single-site failure. Dot budget is also an
issue, so the network engineering team is working to implement a cost-effective redundancy
strategy with a second data center. The new data center must use a three-tier design Identical to the
existing data center. Business requirements dictate that all data must always be accessible from
anywhere in the world, even It a single site fails. The team purchased two Cisco Nexus 7700 Series
Switches and four Catalyst 8000 Series Routers. Which action must the team take to accomplish the
goal?
It’s B because OTV on Nexus handles Layer 2 extension better than NVGRE here.
Makes sense to pick B here. OTV on the Nexus 7700 is designed for extending Layer 2 across data centers, which fits the disaster recovery need perfectly.
daily operational tasks of creating service profile templates. The operations team is unfamiliar with
programming languages and must have a solution that is written in an easy-to-read and declarative
manner. The operations team also requires the tool to be flexible enough to support the creation of
custom modules. The development team is familiar with the Python programming language and can
develop these custom modules for the operations team. Which tool meets these requirements?
A imo, since it’s YAML-based and super simple for ops folks to pick up, plus Python lets devs build custom stuff. Puppet and Chef usually need more coding know-how and aren’t as straightforward for non-programmers.
Option A is a good pick because Ansible uses simple YAML, which is easier for non-programmers, and Python support means the dev team can add custom modules easily. Puppet and Chef are more complex overall.
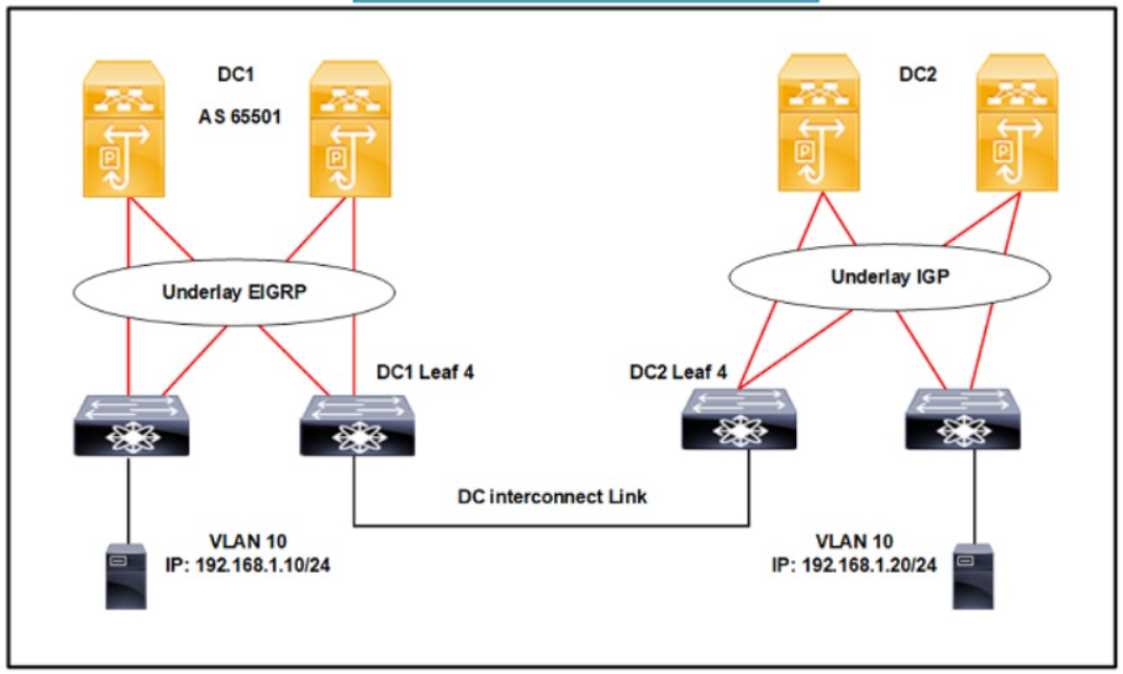
The data center DC1 uses VXLAN technology The company asked a service provider to design another
data center called DC2 and stretch EVPN information between the data centers based on the same
technology The fabric requires
•
endpoint information propagated end-to-end across both data centers
•
misconfiguration replicated from DC1 to DC2
Which actions must the design include in DC2 to meet these criteria?
Refer to the exhibit The data center DC1 uses VXLAN technology The company asked a service
provider to design another data center called DC2 and stretch EVPN information between the data
centers based on the same technology The fabric requires
•
endpoint information propagated end-to-end across both data centers
•
misconfiguration replicated from DC1 to DC2
Which actions must the design include in DC2 to meet these criteria?
It’s A since matching the BGP AS 65500 ensures proper EVPN route propagation, and RIP, though simple, is the only underlay option paired with that AS here. The other protocols don’t align as well with the given AS numbers.
It’s A for me. Matching the BGP AS at 65500 is key since you want to keep the EVPN fabric consistent end-to-end between DC1 and DC2. While RIP isn’t ideal for underlay, it’s the only one listed that pairs with the correct AS number. Options with 65501 don’t match the original DC1 AS, so they’d break the EVPN peering, which messes up endpoint info propagation and misconfiguration replication. So even though RIP isn’t perfect, sticking to the same BGP AS looks like the dealbreaker here.
country at 50 miles between each data center. The data centers must provide redundant network
infrastructure and always be available to customers.
Which two data center design steps must be used to meet these requirements? (Choose two.)
Maybe B and E. B ensures redundancy with active clusters, and E covers data replication across backups, which supports always-on availability across multiple sites. C feels less fitting since async might delay failover.
Wouldn’t A and C work better to ensure local access and proper replication timing?
two.)
B and E, since OTV isolates L3 failures and manages HSRP messages efficiently.
I think A and B are the best picks here. OTV is known for stopping traffic flooding by advertising host reachability directly, which avoids unnecessary broadcast storms. Plus, it keeps layer 3 failures local to each site so problems don’t ripple across all data centers, which is key for multisite reliability.
A customer is deploying a SAN based on Cisco MDS 9000 Series Switches. Each Inter-Switch Link must
carry multiple VSANs at the same time. The access switch must share the same domain ID as the
director switch to reduce the number of domain IDs needed in the fabric Drag and drop the
operational port types from the right onto the boxes on the left to create a topology that meets
these requirements. Not all port types are used. Port types are used more than once.
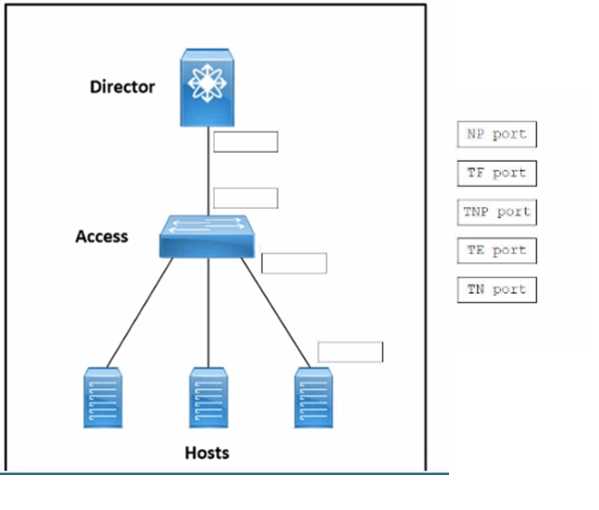
I’m pretty sure the key here is knowing which port types support VSAN trunking. Since multiple VSANs have to run over the ISL, that means it’s gotta be a trunk port type—looks like E is the only one explicitly supporting that. For the shared domain ID, D makes the most sense since that’s what reduces domain IDs by sharing them between switches. The other ports don’t seem to fit those roles because they don’t handle trunking or domain ID sharing. So putting E on the ISL and D on the shared domain ID spot should do the trick.
D is definitely the shared domain ID port; E fits best for multi-VSAN ISLs.
to a specific server in the environment. The solution must apply to network and storage traffic of C-
Series and B-Series servers. Which solution should be included to meet these requirements?
B/C? I’m thinking B because pinning vNICs and vHBAs directly to uplink ports can guarantee bandwidth across both network and storage traffic before it hits the fabrics, which might be more effective for guaranteeing and isolating traffic end-to-end. C seems less likely since IOM ports are more about internal connectivity and might not provide that deterministic control across both server types. So B feels like it covers the bases better for bandwidth guarantees on both C- and B-Series servers.
D, isolating traffic right at the server ports feels more reliable for guaranteed bandwidth.